资源调度:应用程序与操作系统
本文最后更新于 2024-04-14,文章内容可能已经过时。
资源调度:应用程序与操作系统
怎样才能完美的发挥出CPU的性能?
本文主要介绍在计算机演进的过程中,对CPU调度方式的变化,以及应用程序和操作系统对此各自与配合作出的努力。
1.CPU调度:
陈力就列,不能者止。
《论语·季氏》
一个基本的事实前提:一个CPU在一个瞬间只能处理一个任务.
CPU调度的目的,是更好的发挥CPU性能,避免不必要的消耗。
1.1 进程时代:
1.1.1 人工I/O系统:
从1945年诞生的第一台计算机到20世纪50年代中期所出现的计算机,都属于第一代计算机,此时还未出现操作系统(operating system,OS),也不存在程序和进程一说,此时的工作过程全是由人工操作。
早期人工操作过程如下:
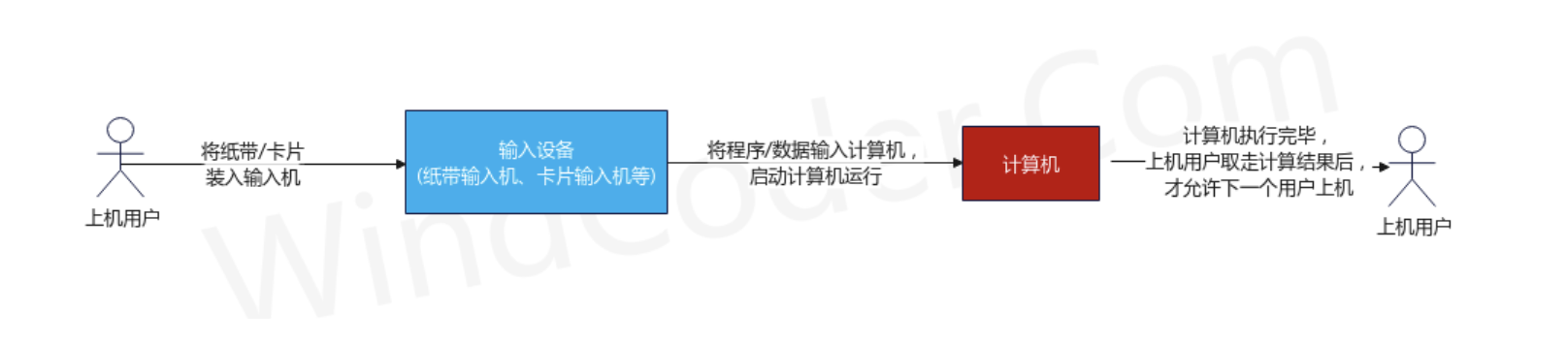
由用户将已打孔的纸带(或卡片)装入纸带输入机(或卡片输入机)
启动输入机将纸带(或卡片)上的程序和数据输入到计算机,然后启动计算机运行。
仅当计算机执行完毕且取走计算结果后,才允许下一个用户上机。
这种方案存在的缺点有:
用户独占全机:计算机的所有资源由当前上机用户独占
CPU 等待人工操作:在上机用户装卸纸带/卡片期间,CPU及内存等资源是空闲的。这种人工操作的方式严重影响了计算机的利用率,这也就是所谓的人机矛盾。虽然 CPU的速度在提高,但I/O输入设备的速度却提升缓慢。
1.1.2 脱机I/O: 单道批处理系统:
单CPU核心-单进程,相当于顺序调度进程。
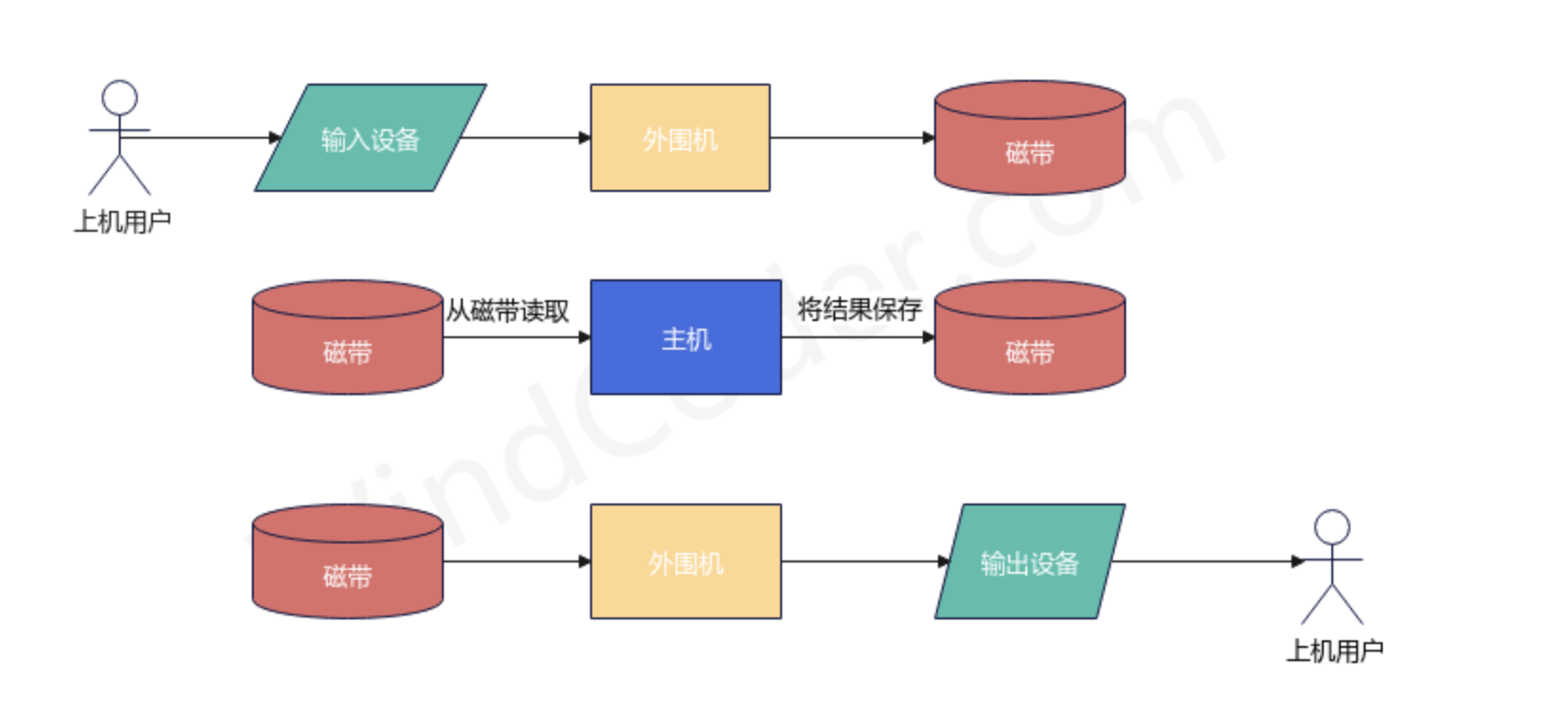
为了解决人机矛盾以及 CPU 与 I/O 设备之间速度不匹配的矛盾,20世纪50年代末出现了脱机I/O模式。其工作原理如下:
事先将将装有用户程序和数据的纸带/卡片装入纸带输入机等输入设备
在一台外围机的控制下,将磁带的数据从输入设备将数据保存到磁带上
当CPU需要这些程序和数据时,再从磁带上将它们高速调入内存中执行。
当CPU需要输出时,先将结果输入到磁带,再在另一个外围机的控制下,将磁带中的结果通过相应的输出设备输出。
这种方案减少了CPU等待时间,提高了I/O速度。
20世纪50年代中期发明了晶体管,人们开始用晶体管替代真空管来制作计算机,从而出现了第二代计算机。
为了能充分地利用它,应尽量使该系统连续运行,减少空闲时间。为此,通常是把一批作业以脱机方式输入到磁带上,并在系统中配上监督程序(Monitor),在它的控制下使这批作业能一个接一个地连续处理。其自动处理过程是:首先,由监督程序将磁带上的第一个作业装入内存,并把运行控制权交给该作业。当该作业处理完成时,又把控制权交还给监督程序,再由监督程序把磁带(盘)上的第二个作业调入内存。计算机系统就这样自动地一个作业一个作业地进行处理,直至磁带(盘)上的所有作业全部完成,这样便形成了早期的批处理系统。
批处理是指用户将一批作业提交给操作系统后就不再干预,由操作系统控制它们自动运行。这种采用批量处理作业技术的操作系统称为批处理操作系统;
批处理操作系统不具有交互性,它是为了提高CPU的利用率而提出的一种操作系统。
但是这种以进程为单位,按照顺序执行的方式有两个显著的问题:
cpu只能一个一个任务的处理
如果发生阻塞,会带来CPU时间的巨大浪费.
1.1.4 多道批处理系统:进程:
单CPU核心-多进程
由于同一时间内存中仅有一道程序,每次该程序发出I/O请求后,CPU都会处于等待状态,直到I/O操作完成才能继续运行。I/O设备自身的低速性导致CPU的利用率明显降低。
为了能执行较大的作业,需要配置较大的内存,但实际多数作业是小型的,占用内存较少,从而造成较多的内存资源浪费。
为了应对这些问题,进一步提高利用率和系统吞吐量,在20世纪60年代中期引入了多道程序设计技术,多道批处理系统由此产生。
在此期间,IBM公司生产了第一台小规模集成电路计算机IBM360,这也是第三代计算机,与此同时,为其设计了OS/360,这是第一个能运行多道程序的批处理系统。
在多道程序环境中,程序的并发执行会失去封闭性,并具有间断性和运行结果不可再现性,所以通常程序是不能直接参与并发的,不然程序的执行便没了意义。为了使程序可以并发执行,并且可以对并发执行的程序加以描述和控制,在 OS 中引入“进程”这一概念。
在引入进程解决单处理机(可以狭隘的认为是单CPU)环境下的程序并发问题后的20年时间里,多道程序的OS(即多道批处理系统)中一直是以进程为能够拥有资源并独立调度/运行的基本单位。
不同的进程应该怎样调度?一开始这种操作系统使用的是时间片轮询算法.
每个进程会被操作系统分配一个时间片,即每次被 CPU 选中来执行当前进程所用的时间。时间一到,无论进程是否运行结束,操作系统都会强制将 CPU 这个资源转到另一个进程去执行。
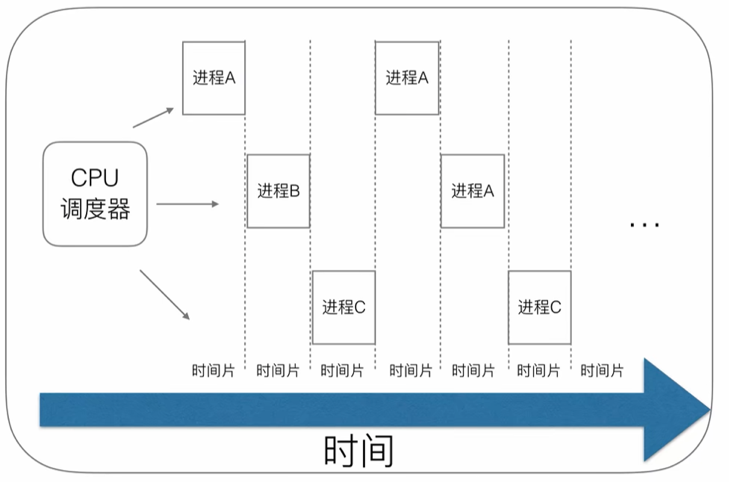
这样做的好处是可以充分的利用CPU的性能,让它在当前线程阻塞(比如各种IO)时可以去操作其他线程.
但是也带来了一些问题,例如时间片切换需要花费额外的开销,线程的数量越多,切换成本就越大,也就越浪费.
进程拥有太多的资源,进程的创建、切换、销毁,都会占用很长的时间,CPU虽然利用起来了,但如果进程过多,CPU有很大的一部分都被用来进行进程调度了.
1.2 线程时代:
1.2.1 线程的产生:
随着时代的发展,出现三个问题:
对应用程序来说,功能越来越多,越来越复杂,使用进程去管理应用程序无法应对全部的问题。
对CPU来说,硬件越来越发达,CPU的核数越来越多,可以并行处理任务,使用进程无法发挥出多核CPU优势。
维护进程的系统开销较大,如创建进程时,分配资源、建立 PCB;终止进程时,回收资源、撤销 PCB;进程切换时,保存当前进程的状态信息;
为了解决这些问题,我们可以设计一种新的方案来管理应用程序。
需要有一种新的实体,满足以下特性:
实体之间可以并发运行;
实体之间共享相同的地址空间;
于是线程出现了。
有了线程以后,CPU在切换时就可以在线程之间来回切换,大大减小了上下文切换资源的浪费.
1.2.2 实现:
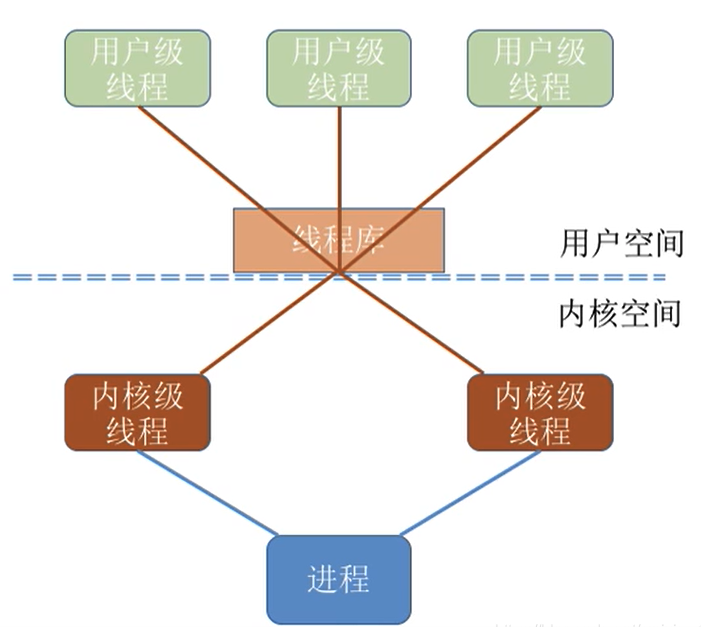
对于线程应该如何实现,有三种实现方式:纯用户级线程、纯内核级线程和混合级线程。
1.2.2.1 纯用户级线程:
用户级线程是在用户空间中实现的,由应用程序自行维护,操作系统并不知道其存在。
优点:
应用程序可以通过调度算法控制线程的执行,由于用户级线程的实现不需要操作系统介入,所以线程的创建和销毁速度较快,上下文切换开销小,适用于轻量级线程的场景。
缺点:
与内核协作成本高:比如这种线程完全是用户空间程序在管理,当它进行 I/O 的时候,无法利用到内核的优势,需要频繁进行用户态到内核态的切换。
线程间协作成本高:设想两个线程需要通信,通信需要 I/O,I/O 需要系统调用,因此用户态线程需要支付额外的系统调用成本。
无法利用多核优势:比如操作系统调度的仍然是这个线程所属的进程,所以无论每次一个进程有多少用户态的线程,都只能并发执行一个线程,因此一个进程的多个线程无法利用多核的优势。
操作系统无法针对线程调度进行优化:当一个进程的一个用户态线程阻塞(Block)了,操作系统无法及时发现和处理阻塞问题,它不会更换执行其他线程,从而造成资源浪费。
1.2.2.2 纯内核级线程:
内核级线程是由操作系统内核管理和调度的,其创建和销毁都由操作系统负责。
优点:
可以利用操作系统的多任务调度机制和同步机制,能够更好地利用多核优势,适用于需要频繁进行阻塞和唤醒操作的线程场景。
缺点:
但是内核级线程通过系统调用来进行线程切换,切换代价较高。
1.2.2.3 混合型线程:
混合级线程结合了用户级线程和内核级线程的优点。
在混合级线程中,用户级线程通过操作系统提供的线程库进行管理,线程库调度器从某进程的多个用户级线程中选择一个线程,然后该线程和该进程允许的一个内核线程关联起来。内核线程将被操作系统调度器指派到处理器内核。
但是线程的阻塞和唤醒操作由内核级线程完成,从而既能够充分利用操作系统的多任务调度机制和同步机制,又能够减小线程切换的代价,提高线程的执行效率。
使用混合型线程,就会出现这样的问题:用户级线程和内核级线程的对应关系是怎样的?
对于这个问题,有三种方案。
1.2.2.3.1 一对一:
一个用户线程唯一的对应一个内核线程(反过来不成立,一个内核线程不一定有对应的用户线程,有可能是闲置的状态)
一个线程由于某种原因阻塞时,其他线程的执行不受影响
可以让多线程序在多处理器的系统上有更好的表现
缺点:
许多操作系统限制了内核线程的数量,所以用户线程的数量也会收到限制
许多操作系统内核线程调度的时候,上下文切换的开销比较大,导致用户线程的执行效率下降。
1.2.2.3.2 多对一:
将多个用户线程映射到一个内核线程上,线程之间的切换由用户态的代码来实现,系统内核感受不到线程的实现方式。
优点: 用户线程的建立、同步、销毁都是在用户态中完成,不需要内核的介入。所以说上下文的切换比较快。 对用户线程的数量几乎没有限制。
缺点:
如果其中一个用户线程阻塞,那么其他所有线程都将无法执行,因为此时内核线程也随之阻塞了。
在多处理器系统上,处理器数量的增加对多对一模型的线程性能不会由明显的增加,因为一个进程的所有的用户线程都映射到一个处理器上了。
1.2.2.3.3 多对多:调度:
多个用户线程映射到多个内核线程上。
由线程库负责在可用的可调度实体上调度用户线程,这使得线程的上下文切换非常快,因为避免了系统调用。
优点:
一个线程的阻塞不会导致所有的线程阻塞,因为此时还有别的内核线程调度来执行。
多对多模型对用户线程的数量没有限制
在多处理器的模型中,多对多模型的线程也能得到一定的性能提升,但提升的幅度不如一对一的大
第三种的优势是一望而知的,一般的混合型线程都会选择第三种实现方案。
1.2.3 多CPU核心-多线程:并发/并行
随着多核CPU性能越来越强,为了更好的利用CPU性能,几乎没有语言和应用程序会选择纯用户态线程,所以都会在纯内核级线程和混合型线程中选择。
于是,各个进程及其线程可以在不同CPU内核上执行。
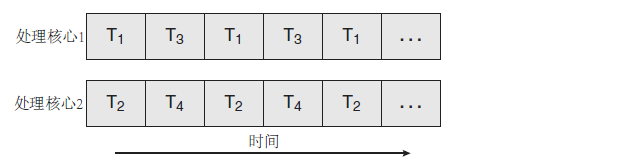
为了便于区分,我们称并发是一个CPU处理器同时处理多个线程任务.可以在一个CPU处理器和多个CPU处理器系统中都存在.(一对多)
并行是多个CPU处理器同时处理多个线程任务.只在多个CPU处理器系统中存在.(多对多)。
1.3 协程时代:
1.3.1 多线程的问题:
近些年,随着网络的发达,多线程应用程序在网络编程中出现了一些问题。
1.3.1.1 网络编程:
与一般的计算机程序相比,网络编程有其独有的特点。
高并发:每秒钟上千数万的单机访问量.
程序生命期周期短:Request/Response.毫秒-秒级.
高IO,低计算:主要功能是连接数据库,请求API等.
1.3.1.2 CPU上下文切换:
多任务操作系统中,多于CPU个数的任务同时运行就需要进行任务调度,从而多个任务轮流使用CPU。
从用户角度看好像所有的任务同时在运行,实际上是多个任务你运行一会,我运行一会,任务切换的速度很快,我们感觉不到而已。
而每个任务运行前,CPU需要知道从哪里加载这个任务的程序,还需要知道从程序哪行开始执行,这就要求OS事先帮任务设置好CPU的 寄存器 和程序计数器 。
CPU执行任务必须依赖的环境称为 CPU上下文。
CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
CPU的上下文切换分为几种场景:进程上下文切换、线程上下文切换、中断上下文切换
1.3.1.2.1 系统调用:
从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容,并调用 write() 将内容写到标准输出,最后再调用 close() 关闭文件。
系统调用会将CPU从用户态切换到核心态,以便 CPU 访问受到保护的内核内存。
系统调用的过程会发生 CPU 上下文的切换,CPU 寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。
而系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换。
注意:系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。
系统调用过程通常称为特权模式切换,而不是进程上下文切换。
1.3.1.2.2 进程上下文切换:
进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
1.3.1.2.3 线程上下文切换:
线程是调度的基本单位,而进程则是资源拥有的基本单位。
所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
当进程只有一个线程时,可以认为进程就等于线程,当进程拥有多个线程时,这些线程会共享进程的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
线程的上下文切换其实就可以分为两种情况:
两个线程属于不同进程,因为资源不共享,切换过程和进程上线文切换一样 两个线程属于同一个进程,只需要切换线程的私有数据、寄存器等不共享的数据
1.3.1.2 问题:
1)一个内核线程的大小通常达到1M,因为需要分配内存来存放用户栈和内核栈的数据;
2)在一个线程执行系统调用(发生 IO 事件如网络请求或读写文件)不占用 CPU 时,需要及时让出 CPU,交给其他线程执行,这时会发生线程之间的切换;
3)线程在 CPU 上进行切换时,需要保持当前线程的上下文,将待执行的线程的上下文恢复到寄存器中,还需要向操作系统内核申请资源;
在高并发的情况下,大量线程的创建、使用、切换、销毁会占用大量的内存,并浪费较多的 CPU 时间在非工作任务的执行上,导致程序并发处理事务的能力降低。
要解决这些问题,我们要尽量减少线程(准确的说是上文的内核线程)的各种调度。为了做到这一点,出现了很多方案。
1.3.2 实现:
1.3.2.1 线程池:Java:
java线程在jdk1.2之前,是基于名为“绿色线程”的(纯)用户线程实现的,这导致绿色线程只能同主线程共享CPU分片,从而无法利用多核CPU的优势。
由于绿色线程和原生线程比起来在使用时有一些限制, jdk1.2中放弃绿色线程,转而使用原生线程。
在目前的jdk版本中,操作系统支持怎样的线程模型,很大程度上决定了java虚拟机的线程是怎样映射的,这点在不同的平台上都没有办法达成一致。
总的来说就是,虚拟机规范中并没有限定java线程需要使用哪种线程模型,要根据不同的平台来说,但是无论使用哪种线程模型,java程序的编码和运行都是没有差异的。
例如,Java SE最常用的JVM是Oracle/Sun研发的HotSpot VM。在这个JVM所支持的所有平台上都是采用一对一的线程模型的,除了Solaris平台。
Java1.5后,Doug Lea的Executor系列被包含在默认的JDK内,是典型的线程池方案。
优点:
线程池一定程度上控制了线程的数量,实现了线程复用,降低了线程的使用成本。
缺点:
但还是没有解决数量的问题,线程池初始化的时候还是要设置一个最小和最大线程数,以及任务队列的长度,自管理只是在设定范围内的动态调整。另外不同的任务可能有不同的并发需求,为了避免互相影响可能需要多个线程池,最后导致的结果就是Java的系统里充斥了大量的线程池。
1.3.2.2 异步回调-代码:NodeJS
最开始的网络程序其实就是一个线程一个请求设计的(Apache)。后来,随着网络的普及,诞生了C10K(C10K 就是 Client 10000 问题,即「在同时连接到服务器的客户端数量超过 10000 个的环境中,即便硬件性能足够, 依然无法正常提供服务」)问题。
Nginx 通过单线程异步 IO 把网络程序的执行流程进行了乱序化,通过 IO 事件机制最大化的保证了CPU的利用率。
当线程运行时遇到阻塞的情况,比如网络调用,则注册一个回调方法(其实还包括了一些上下文数据对象)给IO调度器(linux下是libev,调度器在另外的线程里),当前线程就被释放了,去干别的事情了。(可以理解为,用户态线程的线程被挂起了,但是内核线程没有被挂起,相当于使用挂起用户态线程的方式避免了内核态线程被挂起。)
等数据准备好,调度器会将结果传递给回调方法然后执行,执行其实不在原来发起请求的线程里了,但对用户来说无感知。
举个例子:
// 引入 Node.js 内置的文件系统模块
const fs = require('fs');
// 定义一个异步函数,用于读取文件内容
function readFileContent(filename, callback) {
// 使用 fs.readFile() 方法读取文件内容
fs.readFile(filename, 'utf8', (err, data) => {
// 如果出现错误,将错误传递给回调函数
if (err) {
callback(err, null);
return;
}
// 如果成功读取文件内容,将内容传递给回调函数
callback(null, data);
});
}
// 调用异步函数,读取文件内容,并处理结果
readFileContent('example.txt', (err, data) => {
if (err) {
console.error('读取文件出错:', err);
return;
}
console.log('文件内容:', data);
});缺点:
但这种方式的问题就是很容易遇到callback hell,因为所有的阻塞操作都必须异步,否则系统就卡死了。
还有就是异步的方式有点违反人类思维习惯,人类还是习惯同步的方式。
异步编程为了追求程序的性能,强行的将线性的程序打乱,程序变得非常的混乱与复杂。对程序状态的管理也变得异常困难。写过Nginx C Module的同学应该知道我说的是什么。我们开始吐槽 NodeJS 那恶心的层层Callback。
总的来说,这种方式复杂化了程序代码的编写,非常容易出错。因为线程穿插,也提高排查错误的难度。
1.3.2.3 异步回调-框架:Go:
Go的很多语言特性借鉴与它的三个祖先:C, Pascal和CSP。Go的语法、数据类型、控制流等继承于C, Go的包、面对对象等思想来源于Pascal分支, 而Go最大的语言特色, 基于管道通信的协程并发模型, 则借鉴于CSP分支。
从nodejs的解决方案我们可以看到,异步处理虽然可以带来巨大的性能提升,但是同样会带来巨大的代码复杂性,如何解决这个问题呢?
我们知道,计算机领域中屏蔽复杂性最优秀的方法就是分层,那么我们是否可以将nodejs中的异步的调度交给框架本身去做,让编码人员无感知呢?
1.3.2.3.1 设计:
为了解决传统内核级的线程的创建、切换、销毁开销较大的问题,Go 语言将线程分为了两种类型:内核级线程 M (Machine),轻量级的用户态的协程 Goroutine。通过使用 Goroutine绑定到Machine的方式执行程序。
协程(Coroutine)是在1963年由Melvin E. Conway USAF, Bedford, MA等人提出的一个概念。而且协程的概念是早于线程(Thread)提出的。
Goroutine其实就是前面协程系列解决方案的一种演进和实现。
首先,它内置了Coroutine机制。因为要用户态的调度,必须有可以让代码片段可以暂停/继续的机制。
其次,它内置了一个调度器,实现了Coroutine的多线程并行调度,同时通过对网络等库的封装,对用户屏蔽了调度细节。
最后,提供了Channel机制,用于Goroutine之间通信,实现CSP并发模型(Communicating Sequential Processes)。因为Go的Channel是通过语法关键词提供的,对用户屏蔽了许多细节。其实Go的Channel和Java中的SynchronousQueue是一样的机制,如果有buffer其实就是ArrayBlockQueue。
1.3.2.3.2 实现:
Go语言内部实现上,维护了一组数据结构和 n 个线程,真正的执行还是线程,协程执行的代码被扔进一个待执行队列中,由这 n 个线程从队列中拉出来执行。
golang 对各种 io函数(包括 linux 的 epoll、select 和 windows 的 iocp、event 等。)进行了封装,这些封装的函数提供给应用程序使用,而其内部调用了操作系统的异步 io函数,当这些异步函数返回 busy 或 bloking 时,golang 利用这个时机将现有的执行序列压栈,让线程去拉另外一个协程的代码来执行。
在网络编程中,我们可以理解为 Golang 的协程本质上其实就是对 IO 事件的封装,并且通过语言级的支持让异步的代码看上去像同步执行的一样。
举个例子:
在UNIX中,select()函数用来监控一组描述符,该机制常被用于实现高并发的socket服务器程序。Go语言直接在语言级别支持select关键字,用于处理异步IO问题,大致结构如下:
select{
case <- chan1:
// 如果chan1成功读到数据
case chan2 <- 1:
// 如果成功向chan2写入数据
default:// 默认分支
}select默认是阻塞的,只有当监听的channel中有发送或接收可以进行时才会运行,当多个channel都准备好的时候,select是随机的选择一个执行的。
Go语言没有对channel提供直接的超时处理机制,但我们可以利用select来间接实现,例如:
timeout := make(chan,bool,1)
go func() {
time.Sleep(1e9)
timeout <- true
}()
switch{
case <- ch:
// 从ch中读取到数据
case <- timeout:
// 没有从ch中读取到数据,但从timeout中读取到了数据
}这样使用select就可以避免永久等待的问题,因为程序会在timeout中获取到一个数据后继续执行,而无论对ch的读取是否还处于等待状态。
1.3.2.3.3 执行:
项目启动时,会启动g0与m0:
ok:
// set the per-goroutine and per-mach "registers"
get_tls(BX)
LEAQ runtime·g0(SB), CX
MOVQ CX, g(BX)
LEAQ runtime·m0(SB), AX
// save m->g0 = g0
MOVQ CX, m_g0(AX)
// save m0 to g0->m
MOVQ AX, g_m(CX)
CLD // convention is D is always left cleared
CALL runtime·check(SB)具体执行时,会由调度器(本质上调度器绑定着一个内核线程,会在分配给他的时间片中进行操作,就是调用它自身写好的代码)。把具体的Goroutine绑定到内核线程上。这一般被称作Goroutine切换.
这种切换切换只涉及基本的CPU上下文切换,CPU 上下文,就是一堆寄存器,里面保存了 CPU运行任务所需要的信息:
从哪里开始运行(指令指针寄存器,标识 CPU 运行的下一条指令)
栈顶的位置(堆栈指针寄存器,通常会指向栈顶位置)
当前栈帧在哪(栈帧指针,用于标识当前栈帧的起始位置)
以及其它的CPU的中间状态或者结果(%r12,%r13,%14,%15)
这种切换,本质上就是通过另一个内核线程执行代码,修改内核线程中的数据,而不是什么也不做,坐等内核线程去被操作系统调度器切换。(发送阻塞之后,如果用户态代码不处理,就只能操作系统出手解决问题)
可以看出,这种切换是十分轻量的,远比内核线程小得多。
线程切换:涉及模式切换(从用户态切换到内核态)、16个寄存器、PC、SP...等寄存器的刷新等。
Goroutine切换:只有三个寄存器的值修改 - PC / SP / DX.
至此,我们开始向写PHP一样来写全异步IO的程序。看上去美好极了,仿佛世界就是这样了。
在网络编程中,我们可以理解为 Golang 的协程本质上其实就是对 IO 事件的封装,并且通过语言级/框架级的支持让异步的代码看上去像同步执行的一样。
本质上,Go语言这种设计就是通过框架自动调度和优秀的I/O封装,对多对多混合型线程的一种优秀的实现。
需要注意的是,说Go 适合 IO 密集型,并不准确。更准确的是 Go 适合的是网络 IO 密集型的场景,而非磁盘 IO 密集型。甚至可以说,Go 对于磁盘 IO 密集型并不友好。根本原因:在于网络 socket 句柄和文件句柄的不同。网络 IO 能够用异步化的事件驱动的方式来管理,磁盘 IO 则不行。
1.3.2.4 Actor:
Actor模型是1973年提出的一个分布式并发编程模式, 在Erlang语言中得到广泛支持和应用。
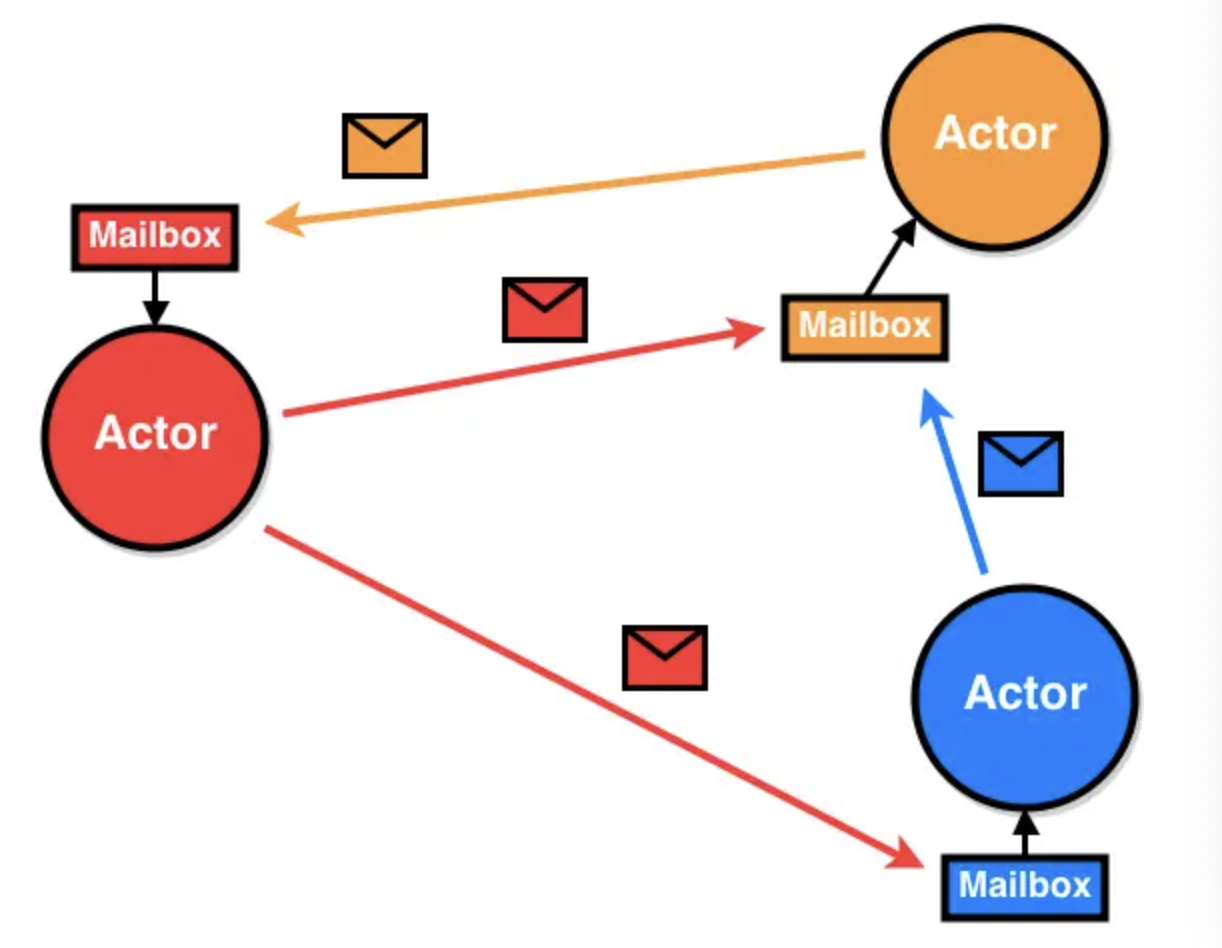
Actor的概念其实和OO里的对象类似,是一种抽象。面对对象编程对现实的抽象是对象=属性+行为(method),但当使用方调用对象行为(method)的时候,其实占用的是调用方的CPU时间片,是否并发也是由调用方决定的。
这个抽象其实和现实世界是有差异的。现实世界更像Actor的抽象,互相都是通过异步消息通信的。
1.3.2.4.1 特征:
Actor有以下特征:
Processing – actor可以做计算的,不需要占用调用方的CPU时间片,并发策略也是由自己决定。
Storage – actor可以保存状态
Communication – actor之间可以通过发送消息通讯
Actor遵循以下规则:
发送消息给其他的Actor
创建其他的Actor
接受并处理消息,修改自己的状态
Actor的目标:
Actor可独立更新,实现热升级。因为Actor互相之间没有直接的耦合,是相对独立的实体,可能实现热升级。
无缝弥合本地和远程调用 因为Actor使用基于消息的通讯机制,无论是和本地的Actor,还是远程Actor交互,都是通过消息,这样就弥合了本地和远程的差异。
容错 Actor之间的通信是异步的,发送方只管发送,不关心超时以及错误,这些都由框架层和独立的错误处理机制接管。
易扩展,天然分布式 因为Actor的通信机制弥合了本地和远程调用,本地Actor处理不过来的时候,可以在远程节点上启动Actor然后转发消息过去。
1.3.2.4.2 实现:
Erlang/OTP Actor模型的标杆,其他的实现基本上都一定程度参照了Erlang的模式。实现了热升级以及分布式。
Akka(Scala,Java)基于线程和异步回调模式实现。由于Java中没有Fiber,所以是基于线程的。为了避免线程被阻塞,Akka中所有的阻塞操作都需要异步化。要么是Akka提供的异步框架,要么通过Future-callback机制,转换成回调模式。实现了分布式,但还不支持热升级。
Quasar (Java) 为了解决Akka的阻塞回调问题,Quasar通过字节码增强的方式,在Java中实现了Coroutine/Fiber。同时通过ClassLoader的机制实现了热升级。缺点是系统启动的时候要通过javaagent机制进行字节码增强。
1.3.2.4.3 在Goroutine上实现Actor:
分布式 解决了单机效率问题,是不是可以尝试解决下分布式效率问题?
和容器集群融合 当前的自动伸缩方案基本上都是通过监控服务器或者LoadBalancer,设置一个阀值来实现的。类似于我前面提到的喂饭的例子,是基于经验的方案,但如果系统内和外部集群结合,这个事情就可以做的更细致和智能。
自管理 前面的两点最终的目标都是实现一个可以自管理的系统。做过系统运维的同学都知道,我们照顾系统就像照顾孩子一样,时刻要监控系统的各种状态,接受系统的各种报警,然后排查问题,进行紧急处理。孩子有长大的一天,那能不能让系统也自己成长,做到自管理呢?虽然这个目标现在看来还比较远,但我觉得是可以期待的。
1.3.2.5 事件循环+回调函数:Python:
1.3.2.5.1 yield:
py3.3 -> py3.8.类似nodejs的方式,有代码侵入性。
程序在运行到 yield 所在的位置 result = yield expr 时, 先执行 yield expr 将产生的值返回给调用生成器的 caller , 然后暂停, 等待 caller 再次激活并恢复程序的执行。而根据恢复程序使用的方法不同, yield expr 表达式的结果值 result 也会跟着变化。 如果使用 next() 来调用, 则 yield 表达式的值 result 是 None;如果使用 send() 来调用, 则 yield 表达式的值 result 是通过 send 函数传送的值。
1.3.2.5.2 yield 与 chan:
yield:
def step(self, future): # 管理fetch生成器: 第一次的激活/暂停后的恢复执行/以及配合set_result循环调用
try:
# send会进入到coro执行, 即fetch, 直到下次yield
# next_future 为yield返回的对象,也就是下一次要调用的Future对象
next_future = self.coro.send(future.result) # __init__中的第一次step,将fetch运行到的82行的yield,
# 返回EVENT_WRITE时的事件回调要用的future,然后等事件触发,由select调用on_connected,进而继续future中的回调
except StopIteration:
return
next_future.add_done_callback(self.step) # 这里需要重点理解,为下一次要调用的Future对象,注册下一次的step,供on_readable调用
while True:
f = Future()
def on_readable():
f.set_result(sock.recv(4096)) # 可读的情况下,读取4096个bytes暂存给Future,执行回调,使生成器继续执行下去
selector.register(sock.fileno(), EVENT_READ, on_readable) # io读事件
chunk = yield f # 返回f,并接受step中send进来的future.result值,也就是暂存的请求返回字符
selector.unregister(sock.fileno())
if chunk:
self.response += chunk
else:
urls_todo.remove(self.url)
if not urls_todo:
stopped = True
break
print("result:", self.response)chan:
var ch chan ElementType
ch := make(chan int)
ch <- value //写入
value := <-ch //读取chunk = yield f,返回f,并接受step中send进来的值,yield暂停子生成器函数的运行把cpu的使用权让出去,对比chan等待其他chan时处于等待中状态(_Gwaiting),是不是有点 chan 的味道了. 子生成器中包含多个yield和带缓存的chan,是不是也有相似呢? python是单线程中调度多个协程,而go是多个进程中调度多个协程,感觉yield和chan是有异曲同工之妙的.
1.3.2.5.3 yield from:
yield from 一方面可以迭代地消耗生成器, 另一方面则建立了一条双向通道, 把最外层的调用方与最内层的子生成器连接起来, 并自动地处理异常, 接收子生成器返回的值。
yield from 更多地被用于协程, 而 await 关键字的引入会大大减少 yield from 的使用频率。
1.3.2.5.4 asyncio:
有一个任务调度器(event loop), 然后可以用async def定义异步函数作为任务逻辑, 通过create_task接口把任务挂到event loop上。 event loop的运行过程应该是个不停循环的过程, 不停查看等待类别有没有可以执行的任务, 如果有的话执行任务, 直到碰到await之类的主动让出event loop的函数, 如此反复。
2.Linux设计与实现:
在操作系统设计上,从进程演化出线程,最主要的目的就是更好的支持SMP以及减小(进程/线程)上下文切换开销。
此部分主要结合操作系统的基本概念,介绍Linux系统对进程,线程等概念的设计。
本节中提到的线程,均为内核线程,也就是说每一个内核线程的执行都有用户态和内核态两种情况。
运行在用户态,也就是用户空间的内核线程,与用户态线程是不同的概念。
2.1 系统启动:
主板上的ROM固化了一段初始化程序BIOS(Basic Input and Output System,基本输入输出系统)
Grub2是一个linux启动管理器 ,Grub2把boot.img共512字节安装到启动盘的第一个扇区,这个扇区称为MBR(Master Boot Record,主引导记录扇区)。
主机上电后,CS重置为0xFFFF,IP重置为0x0000,所以第一条指令指向0xFFFF0,正好在ROM范围内,从这里开始进行硬件检查
将磁盘引导扇区读入0x7c00处,并从0x7c000开始执行
boot模块:bootsect.s,继续读取其它扇区
setup模块:setup.s
从实模式切换到保护模式(CR0寄存器最后一位置1)
初始化GDT,IDT
system模块:许多文件(head.s,main.c ...)
进入main函数,进入各种初始化操作。
系统创建第一个进程,即0号进程,这是唯一一个没有通过fork或者kernel_thread产生的进程,是进程列表的第一个进程
从内核态到用户态,创建第二个进程,这个是1号进程。 1号进程即将运行一个用户进程
0号进程 -> 1号内核进程 -> 1号用户进程(init进程) -> getty进程 -> shell进程 -> 命令行执行进程。
加载内核:打开电源后,加载BIOS(只读,在主板的ROM里),硬件自检,读取MBR(主引导记录),运行Boot Loader,内核就启动了,这里还有从实模式到保护模式的切换
进程:内核启动后,先启动第0号进程init_task,然后在内核运行init()函数,1号进程进入用户态变为init进程,init进程是所有用户态进程的老祖宗,其配置文件是/etc/inittab,通过该文件设置运行等级:根据/etc/inittab文件设置运行等级,比如有无网络
系统初始化:启动第一个用户层文件/etc/rc.d/rc.sysinit,然后激活交换分区、检查磁盘、加载硬件模块等
建立终端:系统初始化后返回init,这时守护进程也启动了,init接下来打开终端以供用户登录
总结:
init_task是第0号进程,唯一一个没有通过fork或kernel_thread产生的进程,是进程列表的第一个
init是第1号进程,会成为用户态,是所有用户态进程的祖先
kthreadd是第2号进程,会成为内核态,是所有内核态进程的祖先
2.2 进程与线程:
2.2.1 数据结构:
Linux中,线程和进程使用同一个task_struct结构:
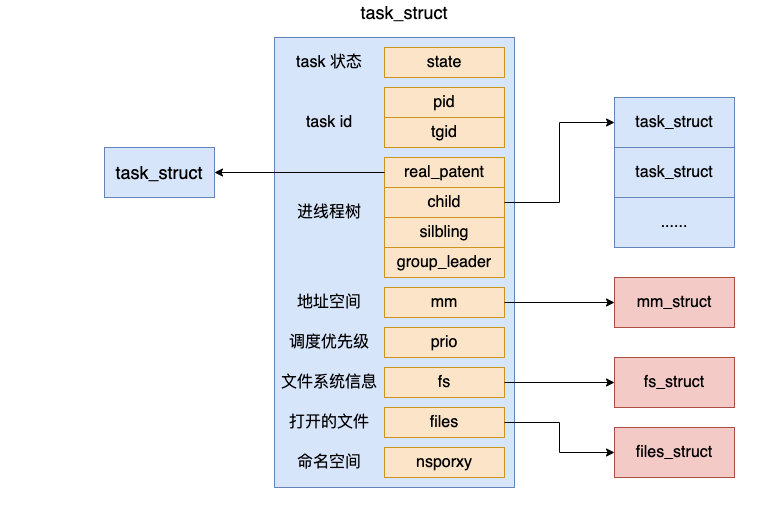

每个task_struct使用pid作为唯一标识,对于进程来说,这个 pid 就是我们平时常说的进程 pid,对于线程来说,通过 tgid 字段来表示自己所归属的进程 ID。
按照操作系统的设计来看,PCB和TCB在Linux中都是task_struct。
2.2.1 创建:
2.2.1.1 过程:
进程线程创建的时候,使用的函数看起来不一样。但实际在底层实现上,最终都是使用同一个函数来实现的。
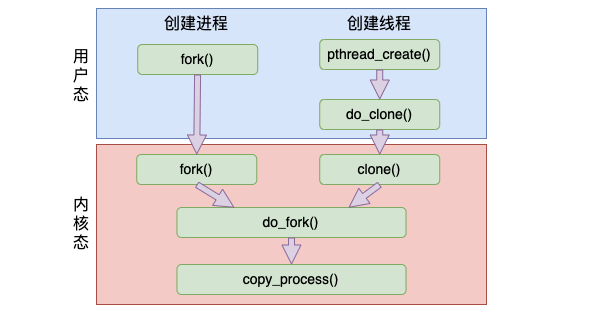
和创建进程时使用的 fork 系统调用相比,创建线程的 clone 系统调用几乎和 fork 差不多,也一样使用的是内核里的 do_fork 函数,最后走到 copy_process() 来完整创建。
不过创建过程的区别是二者在调用 do_fork 时传入的 clone_flags 里的标记不一样。
创建进程时的 flag:仅有一个 SIGCHLD
创建线程时的 flag:包括 CLONE_VM、CLONE_FS、CLONE_FILES、CLONE_SIGNAL、CLONE_SETTLS、CLONE_PARENT_SETTID、CLONE_CHILD_CLEARTID、CLONE_SYSVSEM。
CLONE_VM: 新 task 和父进程共享地址空间
CLONE_FS:新 task 和父进程共享文件系统信息
CLONE_FILES:新 task 和父进程共享文件描述符表
2.2.1.2 do_fork()函数:
部分源码如下:
// kernel/fork.c
/* For compatibility with architectures that call do_fork directly rather than
* using the syscall entry points below. */
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
// 调用统一的创建进程方法
return _do_fork(clone_flags, stack_start, stack_size,
parent_tidptr, child_tidptr, 0);
}
/*
* Ok, this is the main fork-routine.
*
* It copies the process, and if successful kick-starts
* it and waits for it to finish using the VM if required.
*/
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
struct completion vfork;
struct pid *pid;
struct task_struct *p;
int trace = 0;
long nr;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
// 复制当前进程上下文信息
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls, NUMA_NO_NODE);
add_latent_entropy();
if (IS_ERR(p))
return PTR_ERR(p);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
trace_sched_process_fork(current, p);
// 获取新创建的进程id
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
// 将新进程放入调度队列,以便后续可以被执行
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
// 进程id管理
put_pid(pid);
return nr;
}这个函数可以理解为:先复制当前进程,然后将其唤醒等待调度,然后返回进程id。
2.2.1.3 copy_process()函数:
部分源码如下:
//file:kernel/fork.c
static struct task_struct *copy_process(...)
{
//复制进程 task_struct 结构体
struct task_struct *p
p = dup_task_struct(current);
...
//拷贝 files_struct
retval = copy_files(clone_flags, p);
//拷贝 fs_struct
retval = copy_fs(clone_flags, p);
//拷贝 mm_struct
retval = copy_mm(clone_flags, p);
//拷贝进程的命名空间 nsproxy
retval = copy_namespaces(clone_flags, p);
//申请 pid && 设置进程号
pid = alloc_pid(p->nsproxy->pid_ns);
p->pid = pid_nr(pid);
p->tgid = p->pid;
if (clone_flags & CLONE_THREAD)
p->tgid = current->tgid;
......
}具体过程如下:
2.2.1.3.1 复制 task_struct 结构体:
。在 dup_task_struct 里,会申请一个新的 task_struct 内核对象,然后将当前任务复制给它。需要注意的是,这次拷贝只会拷贝 task_struct 结构体本身,它内部包含的 mm_struct 等成员不会被复制。
2.2.1.3.2 拷贝打开文件列表:
我们先回忆一下前面的内容,创建线程调用 clone 系统调用的时候,传入了一堆的 flag,其中有一个就是 CLONE_FILES。如果传入了 CLONE_FILES 标记,就会复用当前进程的打开文件列表 - files 成员。
对于创建进程来讲,没有传入这个标志,就会新创建一个 files 成员出来。
2.2.1.3.3 拷贝文件目录信息:
再回忆一下创建线程的时候,传入的 flag 里也包括 CLONE_FS。如果指定了这个标志,就会复用当前进程的文件目录 - fs 成员。
对于创建进程来讲,没有传入这个标志,就会新创建一个 fs 出来。
2.2.1.3.4 拷贝内存地址空间:
创建线程的时候带了 CLONE_VM 标志,而创建进程的时候没带。接下来在 copy_mm 函数 中会根据是否有这个标志来决定是该和当前线程共享一份地址空间 mm_struct,还是创建一份新的。
2.2.1.4 总结:
对于线程来讲,其地址空间 mm_struct、目录信息 fs_struct、打开文件列表 files_struct 都是和创建它的任务共享的。
但是对于进程来讲,地址空间 mm_struct、挂载点 fs_struct、打开文件列表 files_struct 都要是独立拥有的,都需要去申请内存并初始化它们。
在 Linux 内核中并没有对线程做特殊处理,还是由 task_struct 来管理。从内核的角度看,用户态的线程本质上还是一个进程。只不过和普通进程比,稍微“轻量”了那么一些。
2.3 用户态与内核态:
用户态与内核态的主语是进程/线程/内核线程。
2.3.1 指令特权级:
在 CPU 的所有指令中,有些指令是非常危险的,如果错用,将导致系统崩溃,比如清内存、设置时钟等。如果允许所有的程序都可以使用这些指令,那么系统崩溃的概率将大大增加。
所以,CPU 将指令分为特权指令和非特权指令,对于那些危险的指令,只允许操作系统及其相关模块使用,普通应用程序只能使用那些不会造成灾难的指令。比如 Intel 的 CPU 将特权等级分为 4 个级别:Ring0~Ring3。 其实 Linux 系统只使用了 Ring0 和 Ring3 两个运行级别(Windows 系统也是一样的)。当进程/线程运行在 Ring3 级别时被称为运行在用户态,而运行在 Ring0 级别时被称为运行在内核态。
2.3.2 切换:
进程/线程由用户态切换到内核态有三种方式:
2.3.2.1 系统调用:
int指令将CS中的CPL改为0,从而进入内核,这是用户程序发起调用内核代码的唯一方式
这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作,比如前例中fork()实际上就是执行了一个创建新进程的系统调用。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的int 80h中断。
2.3.2.2 异常:
当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
2.3.2.3 外围设备的中断:
当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
2.3.3 用户栈与内核栈:
Linux内核在创建进程/线程的时候,也就是在创建task_struct的同时,会为进程创建相应的堆栈。
每一个进程/线程都有两个栈,一个用户栈,存在于用户空间;一个内核栈,存在于内核空间。
当进程/线程在用户空间运行时,CPU堆栈指针寄存器里面的内容都是用户栈地址,使用用户栈;当进程在内核空间运行时,CPU堆栈指针寄存器里面的内容是内核栈地址,使用内核栈。
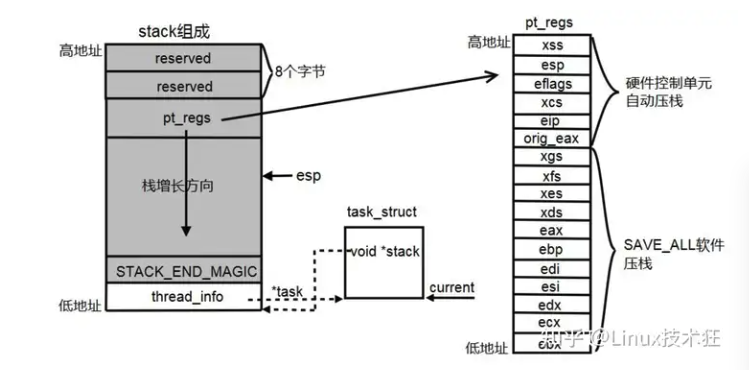
2.3.3.1 切换:
当进程因为中断或者系统调用陷入到内核态时,进程所使用的堆栈也要从用户栈转到内核栈。
进程陷入到内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,*这样就完成了用户栈向内核栈的转换;当进程从内核态恢复到用户态时*,在内核态之后的最后将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈向用户栈的转换
在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为当进程在用户态运行时使用用户栈,当进程陷入到内核态时,内核保存进程在内核态运行的相关信息,但是一旦进程返回到用户态后,内核栈中保存的信息全部无效,因此每次进程从用户态陷入内核的时候得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了。
2.5 发展历史:
2.5.1 早期:
Linux内核在 2.0.x版本就已经实现了轻量进程,应用程序可以通过一个统一的clone()系统调用接口,用不同的参数指定创建轻量进程还是普通进程。在内核中, clone()调用经过参数传递和解释后会调用do_fork(),这个核内函数同时也是fork()、vfork()系统调用的最终实现。
2.5.2 LinuxThreads:LWP:
轻量级进程(LWP)是建立在内核之上并由内核支持的用户线程,它是内核线程的高度抽象,每一个轻量级进程都与一个特定的内核线程关联。内核线程只能由内核管理并像普通进程一样被调度。
为了引入多线程,Linux2.0~2.4实现的是俗称LinuxThreads的多线程方式。
这种实现本质上是一种LWP的实现方式,即通过轻量级进程来模拟线程,内核并不知道有线程这个概念,在内核看来,都是进程。
Linux采用的“一对一”的线程模型,即一个LWP对应一个线程。这个模型最大的好处是线程调度由内核完成了,而其他线程操作(同步、取消)等都是核外的线程库函数完成的。
在LinuxThreads中,专门为每一个进程构造了一个管理线程,负责处理线程相关的管理工作。当进程第一次调用pthread_create()创建一个线程的时候就会创建并启动管理线程。然后管理线程再来创建用户请求的线程。也就是说,用户在调用pthread_create后,先是创建了管理线程,再由管理线程创建了用户的线程。
但是这种设计有些不足,准确的说,不满足POSIX标准:
1: 查看进程列表的时候, 相关的一组task_struct应当被展现为列表中的一个节点; 2: 发送给这个"进程"的信号(对应kill系统调用), 将被对应的这一组task_struct所共享, 并且被其中的任意一个"线程"处理; 3: 发送给某个"线程"的信号(对应pthread_kill), 将只被对应的一个task_struct接收, 并且由它自己来处理; 4: 当"进程"被停止或继续时(对应SIGSTOP/SIGCONT信号), 对应的这一组task_struct状态将改变; 5: 当"进程"收到一个致命信号(比如由于段错误收到SIGSEGV信号), 对应的这一组task_struct将全部退出;
因此,这种设计存在着存在一些比较严重的问题:
1)线程ID和进程ID的问题 按照POSIX的定义,同一进程的所有的线程应该共享同一个进程和父进程ID,而Linux的这种LWP方式显然不能满足这一点。
2)信号处理问题 异步信号是以进程为单位分发的,而Linux的线程本质上每个都是一个进程,且没有进程组的概念,所以某些缺省信号难以做到对所有线程有效,例如SIGSTOP和SIGCONT,就无法将整个进程挂起,而只能将某个线程挂起。
3)线程总数问题 LinuxThreads将每个进程的线程最大数目定义为1024,但实际上这个数值还受到整个系统的总进程数限制,这又是由于线程其实是核心进程。
4)管理线程问题 管理线程容易成为瓶颈,这是这种结构的通病;同时,管理线程又负责用户线程的清理工作,因此,尽管管理线程已经屏蔽了大部分的信号,但一旦管理线程死亡,用户线程就不得不手工清理了,而且用户线程并不知道管理线程的状态,之后的线程创建等请求将无人处理。
5)同步问题 LinuxThreads中的线程同步很大程度上是建立在信号基础上的,这种通过内核复杂的信号处理机制的同步方式,效率一直是个问题。
6)其他POSIX兼容性问题 Linux中很多系统调用,按照语义都是与进程相关的,比如nice、setuid、setrlimit等,在目前的LinuxThreads中,这些调用都仅仅影响调用者线程。
7)实时性问题 线程的引入有一定的实时性考虑,但LinuxThreads暂时不支持,比如调度选项,目前还没有实现。不仅LinuxThreads如此,标准的Linux在实时性上考虑都很少。
2.5.3 NPTL:
到了linux 2.6, glibc中有了一种新的pthread线程库–NPTL(Native POSIX Threading Library).
本质上来说,NPTL还是一个LWP的实现机制,但相对原有LinuxThreads来说,做了很多的改进。
在linux 2.6中, 内核有了线程组的概念, task_struct结构中增加了一个tgid(thread group id)字段.
如果这个task是一个”主线程”, 则它的tgid等于pid, 否则tgid等于进程的pid(即主线程的pid).
在clone系统调用中, 传递CLONE_THREAD参数就可以把新进程的tgid设置为父进程的tgid(否则新进程的tgid会设为其自身的pid).
类似的XXid在task_struct中还有两 个:task->signal->pgid保存进程组的打头进程的pid、task->signal->session保存会话 打头进程的pid。通过这两个id来关联进程组和会话。
有了tgid, 内核或相关的shell程序就知道某个tast_struct是代表一个进程还是代表一个线程, 也就知道在什么时候该展现它们, 什么时候不该展现(比如在ps的时候, 线程就不要展现了).
3.未来:
No Silver Bullet.
《没有银弹:软件工程的本质性与附属性工作》(英语:No Silver Bullet—Essence and Accidents of Software Engineering)是IBM大型机之父佛瑞德·布鲁克斯所发表一篇关于软件工程的经典论文,原先是在1986年都柏林IFIP研讨会的一篇受邀论文,隔年电机电子工程师学会《Computer》也转载了这篇文章,他们用了几张《伦敦狼人》之类的电影剧照来当作说明,还加上了一段〈终结狼人〉的附注,用来引出非银弹则不能成功的(现代)传说。该论述中强调由于软件的复杂性本质,而使真正的银弹并不存在;所谓的没有银弹是指没有任何一项技术或方法可使软件工程的生产力在十年内提高十倍。
不论是异步I/O的模型,还是协程模型,本身仍然存在各种各样的问题。
在当今的云原生环境下,应用程序在各自的容器内工作,他们各自的进程/线程/用户态线程如何管理?如何进行通信?是否还有优化空间?
或者,是否可以用Go语言这种异步编程语言开发操作系统?比较完美的发挥出它调度CPU的能力?但是这样会不会丧失原本的优势?无法编排和控制调度到每个不同的应用程序本身?
在语言中显示自身的东西, 我们无法用语言来表示它。
维特根斯坦
这句话不太好理解, 请允许我做一个不负责任的类比。
比如计算机编程, 逻辑相当于机器语言或者汇编语言, 反正是比较底层的那种;人的语言相当于高级编程语言, 类似java和python;我们的生活就是软件的图形界面。
如果你是一个工程师, 你一定是顺着理解这件事的——机器语言一定是基础啊, 它是一切得以运作绝对前提啊。维特根斯坦会说, 幼稚!我当年也是这么想的他说, 必须倒过来理解。因为人和图形界面的交互, 才会有高级语言的各种安排, 才会有机器语言的各种运作。
为什么?因为人才是一切的尺度, 人这个主体和软件界面产生交互模式(人和生活), 最终决定了你那些0和1的意义(语言和逻辑)。
维特根斯坦那句话的意思是, 你从图形界面的维度能解释为什么这行代码要这样写, 但你在这行代码的维度解释不了它为什么会被写成这样, 在人与图形界面交互的过程中, 这段字符承载的意义远超过这段字符本身所显示的全部, 代码的意义在于使用, 「语言的意义也在于使用」, Meaning is use! 简单理解, 维特根斯坦的整个逻辑是:底层原理能解释表层现象, 但反过来却不行。
表层最多能描述底层。 比如, 人性能解释商业为什么是那个样子的, 但商业却不能解释人性为什么是那个样子, 商业只能从它所在的侧面描述人性是什么样的, 因为商业形式就是被人性塑造的。之前, 我们以为代码是底层, 图形是表层。其实, 图形才是底层, 代码是表层, 这里的意思是, 生活能解释语言, 语言却只能描述生活。语言妄图解释生活, 表层妄图解释底层的结果就是哲学的出现。
这样就造就了一个可悲的事实,即人类对自然的认识永远只能无限的接近真理, 却永远无法探究到所谓的本源, 认识自然的过程其实都是在盲人摸象。
从实际出发, 不同问题用不同方法, 一个模型是否可靠, 看的从来不是理论或模型是否高明, 检验真理的唯一标准只有一条, 就是实践, 自己动手去尝试证实。
