规则引擎基本概念
本文最后更新于 2023-10-11,文章内容可能已经过时。
规则引擎
1.介绍:
规则引擎是一种嵌入在应用服务中的组件,可以将灵活多变的业务决策从服务代码中分离出来。通过使用预定义的语义模块来编写业务逻辑规则。在执行时接受数据输入、解释业务规则,并做出决策。规则引擎能大大提高系统的灵活性和扩展性。
在字节跳动,规则引擎已经在风控识别、活动运营、配置下发等场景得到了广泛的应用。开发人员可以将业务逻辑与服务代码解耦,实现灵活、高效的业务策略发布。目前公司内部基于规则引擎的动态决策系统已经承接了千万级别QPS的决策请求。
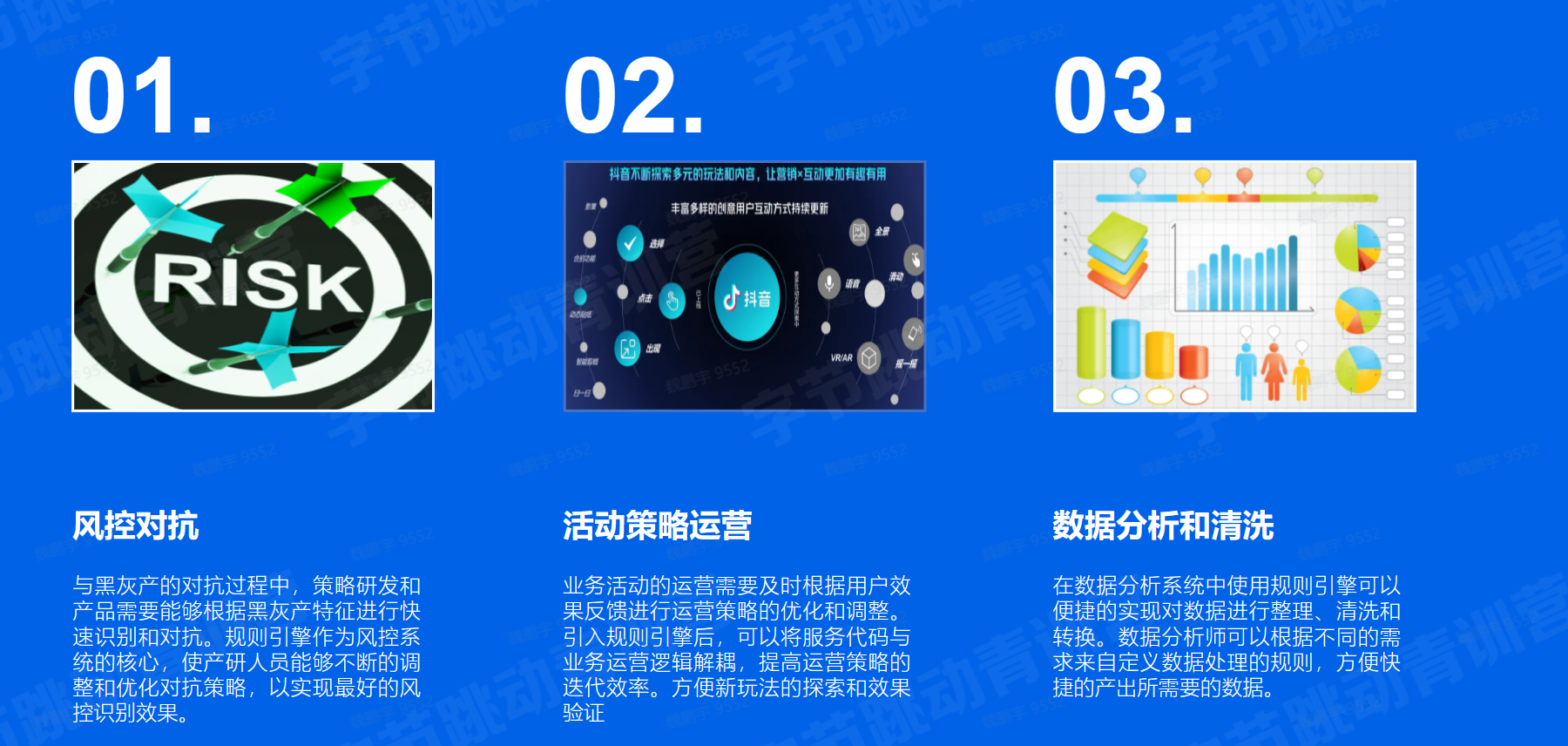
规则引擎的实现需要在满足大容量、高请求、低延迟的基础上尽可能做到简单易上手。本次课程将会带领大家实现一个简单版的规则引擎。
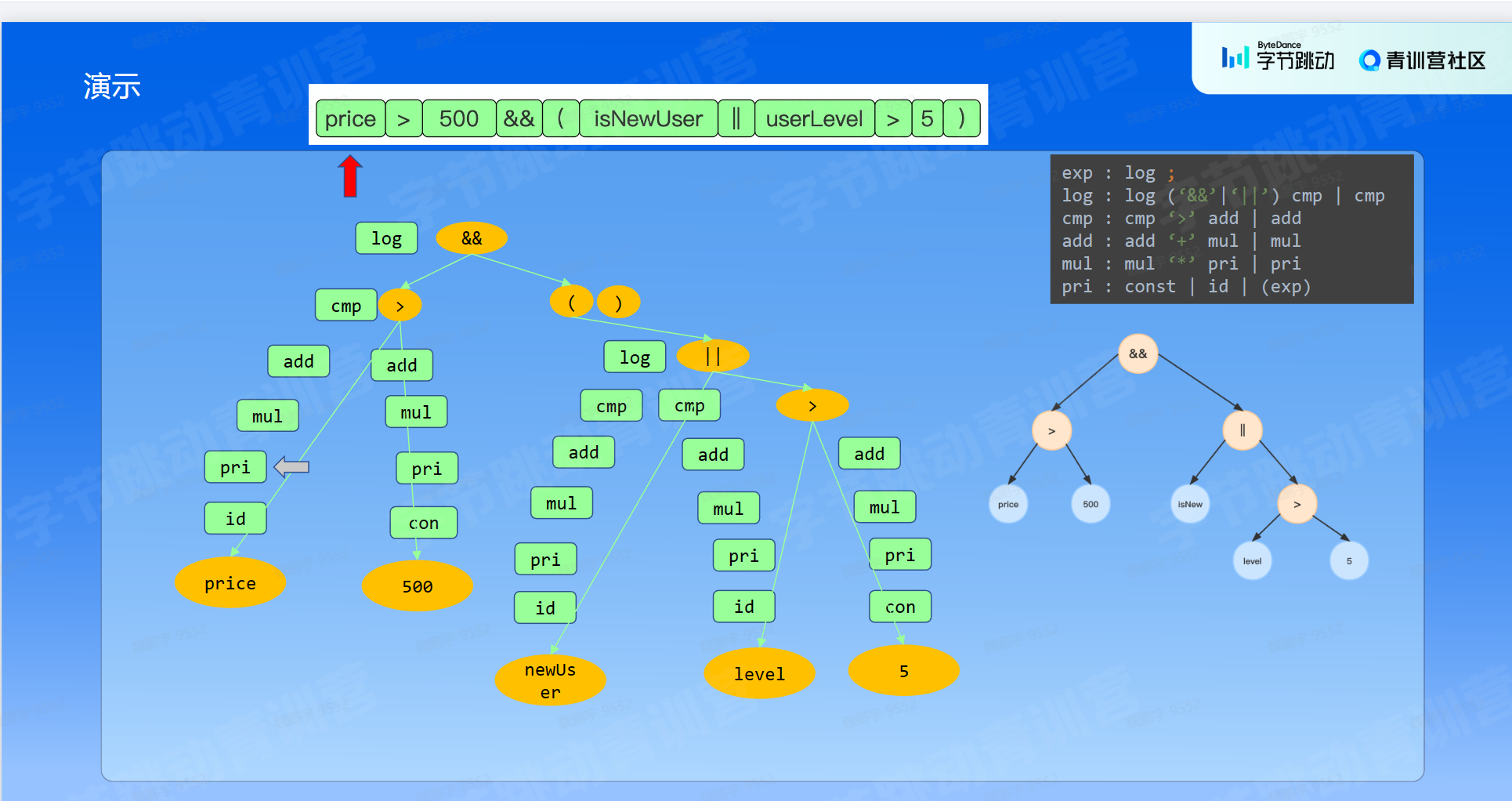
规则引擎的本质呢就是我们自己定义一套语法,然后去解析用这套语法写的表达式,然后根据解析的内容执行表达式。这个过程其实就是编译和执行的过程。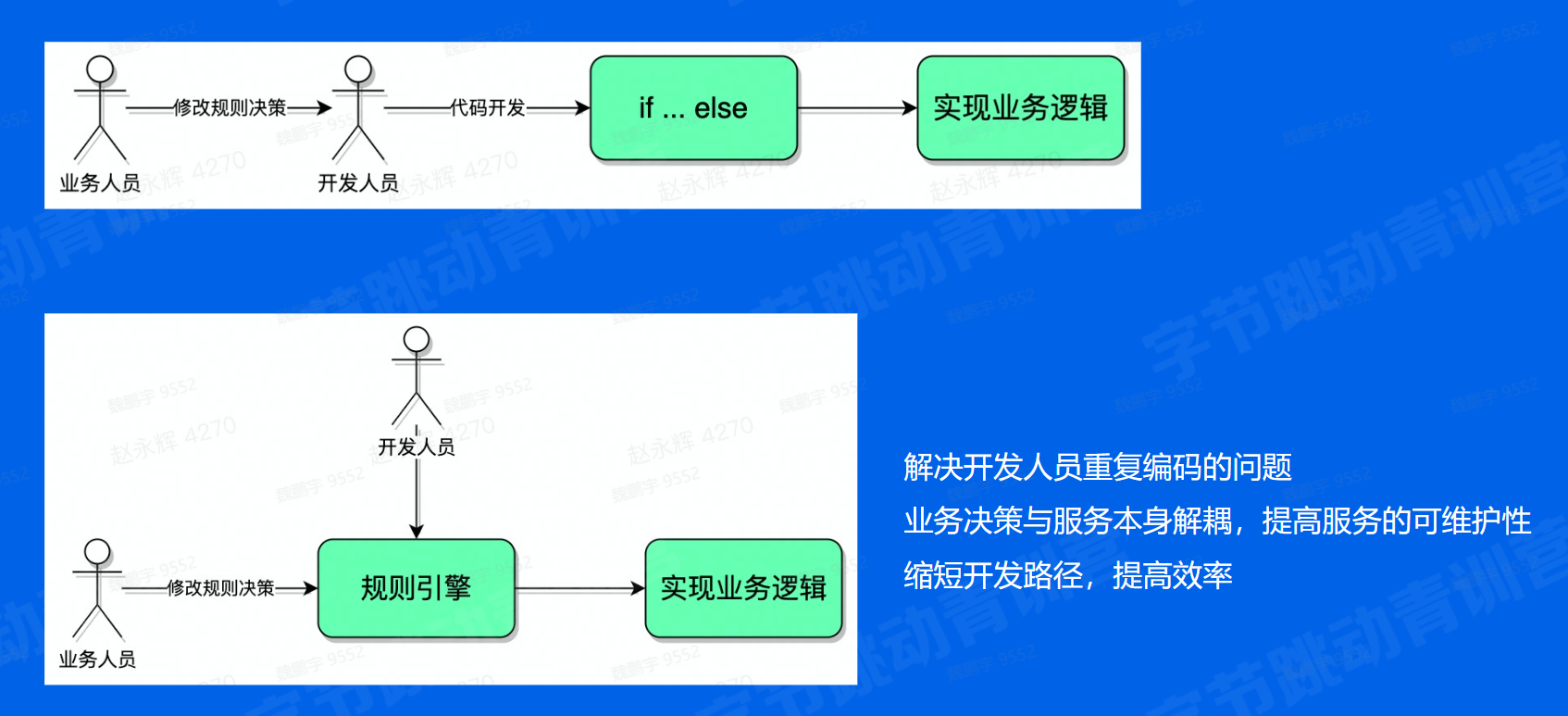
1.1 组成部分:

2.编译原理基本概念:
2.1 编译:
编译的过程就是把某种语言的源程序,在不改变语义的条件下,转换成另一种语言程序(目标语言程序)
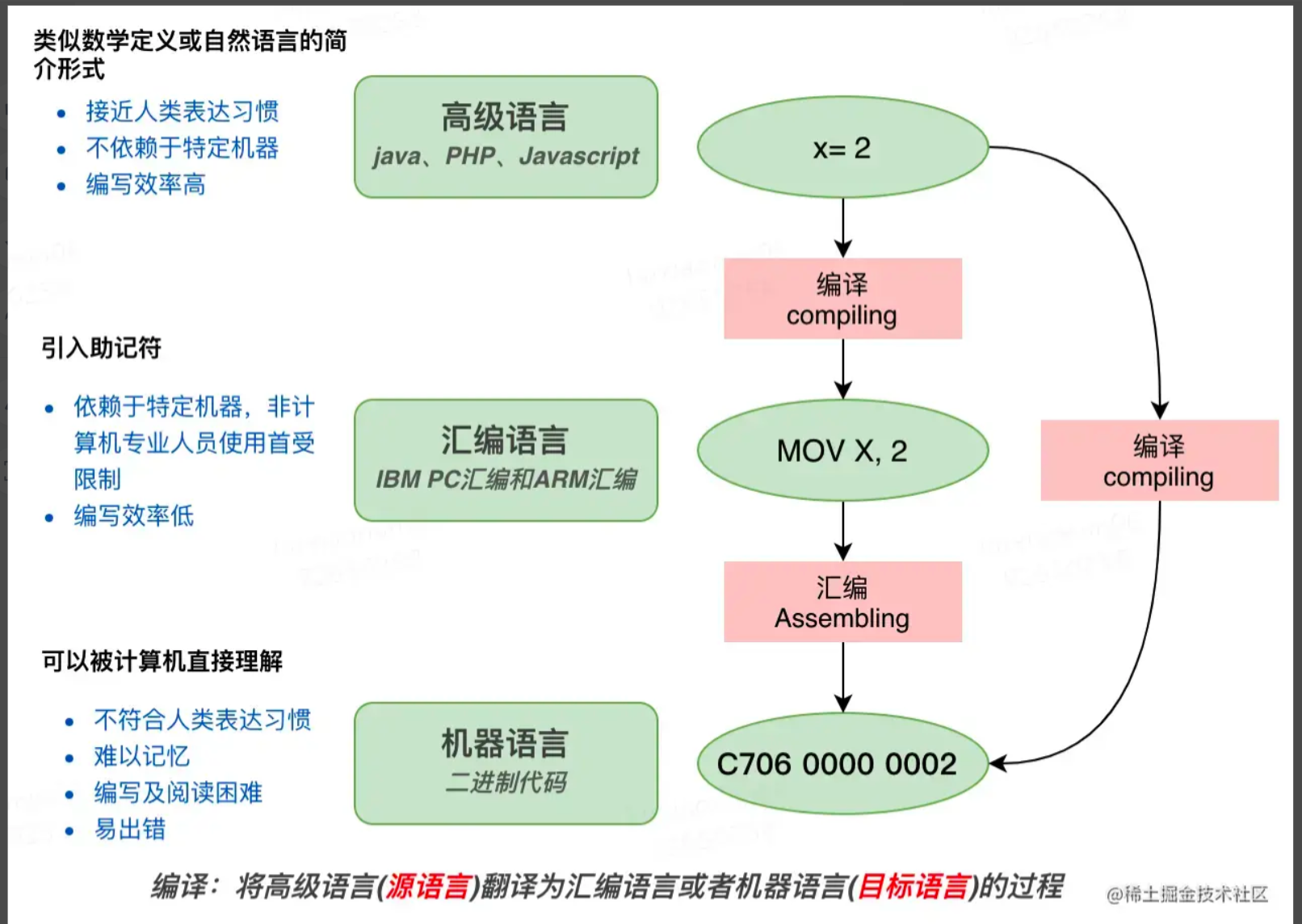
如果源代码编译后要在操作系统上运行,那目标代码就是汇编/机器代码。
如果编译后是在虚拟机里执行,那目标代码就可以不是汇编代码,而是一种解释器可以理解的中间形式的代码即可。
2.1.1 解释型语言和编译型语言:
有的语言提前把代码一次性转换完毕,这种就是编译型语言,用的转换工具就叫编译器,比如C、C++、Go。一次编译可重复执行
编译后产物不能跨平台,不同系统对可执行文件的要求不同。.exe
特殊的,c、c++、汇编、源代码也不能跨平台
有的语言则可以一边执行一边转化,用到哪里了就转哪里,这种就是解释性语言,用的转化工具叫虚拟机或者解释器,比如java python、javascript
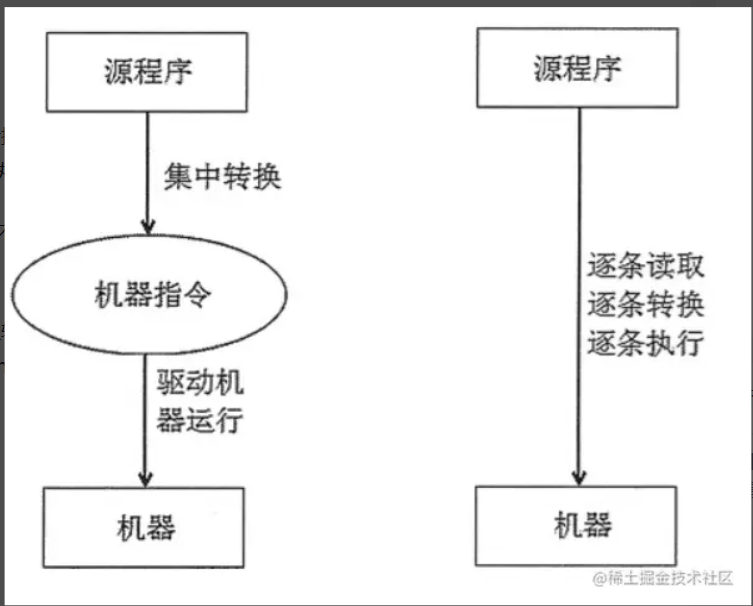
关于 Java 和 Python .
Java既有编译又有解释。但是编译并没有直接编译成机器码,而是编译成字节码,然后再放到虚拟机中执行。
Python执行过程也是经过两个阶段,先编译成字节码 .pyc 再放到虚拟机中去执行
JVM 和 Python解释器 | 为什么一个叫虚拟机一个叫解释器
“虚拟机”对二进制字节码进行解释,而“解释器”是对程序文本进行解释。
从历史上看,Java 是为解释二进制字节码而设计和实现的,而 Python 最初是为解释程序文本而设计和实现的。因此,“Java 虚拟机”这个术语在 Java 社区中具有历史意义并且非常成熟,“Python 解释器”这个术语在 Python 社区中具有历史意义并且非常成熟。人们倾向于延长传统并使用很久以前使用的相同术语。
对于 Java,二进制字节码解释是程序执行的主要方式,而 JIT 编译只是一种可选的和透明的优化。而对于 Python,目前,程序文本解释是 Python 程序执行的主要方式,而编译成 Python VM 字节码只是一种可选的透明优化。
2.2: 过程:
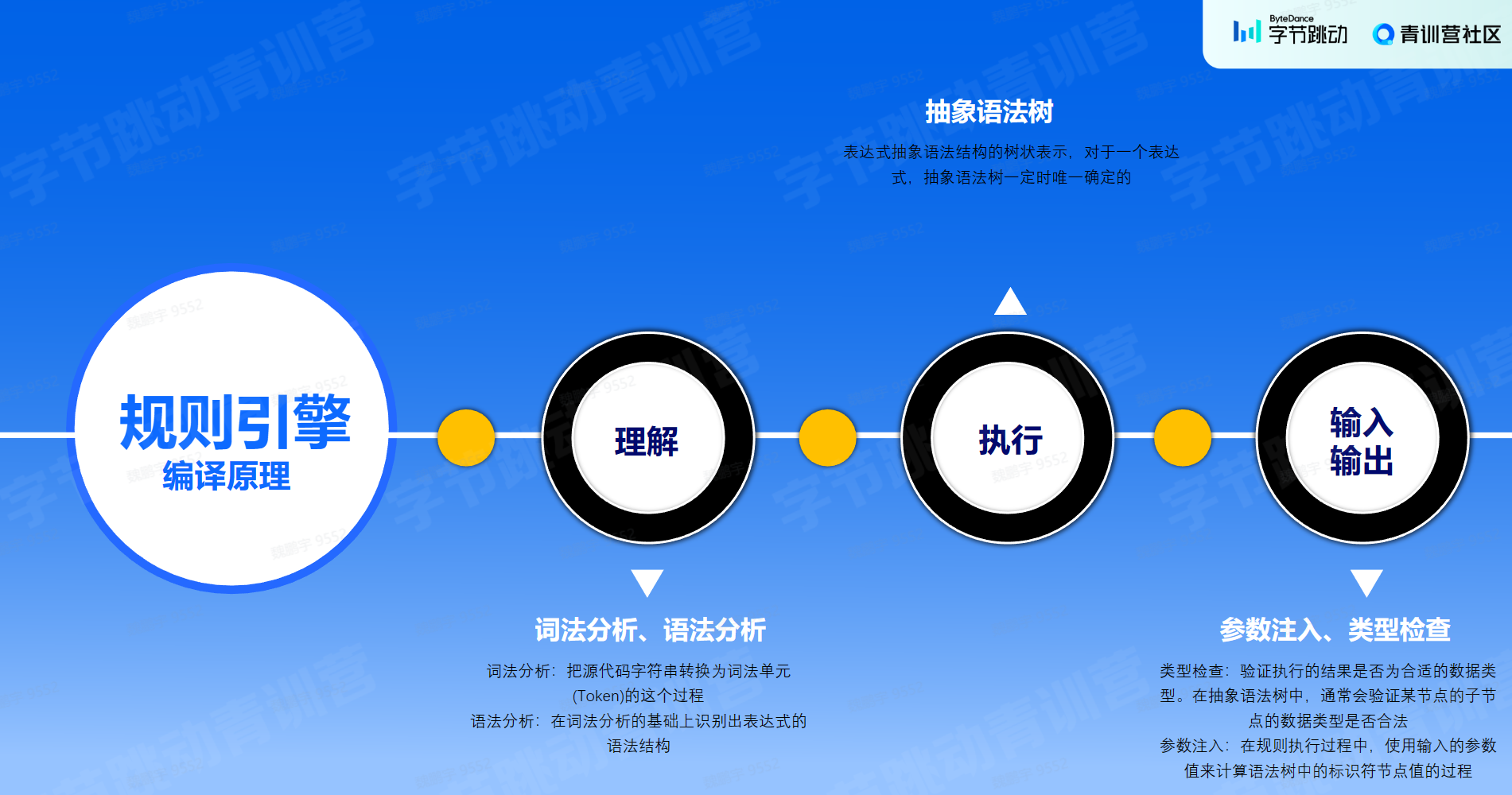
2.2.1: 词法分析:
词法分析是规则引擎的第一步,通过逐行解析源代码,把源代码当成字符串解析,转换为词法单元(Token)的过程。
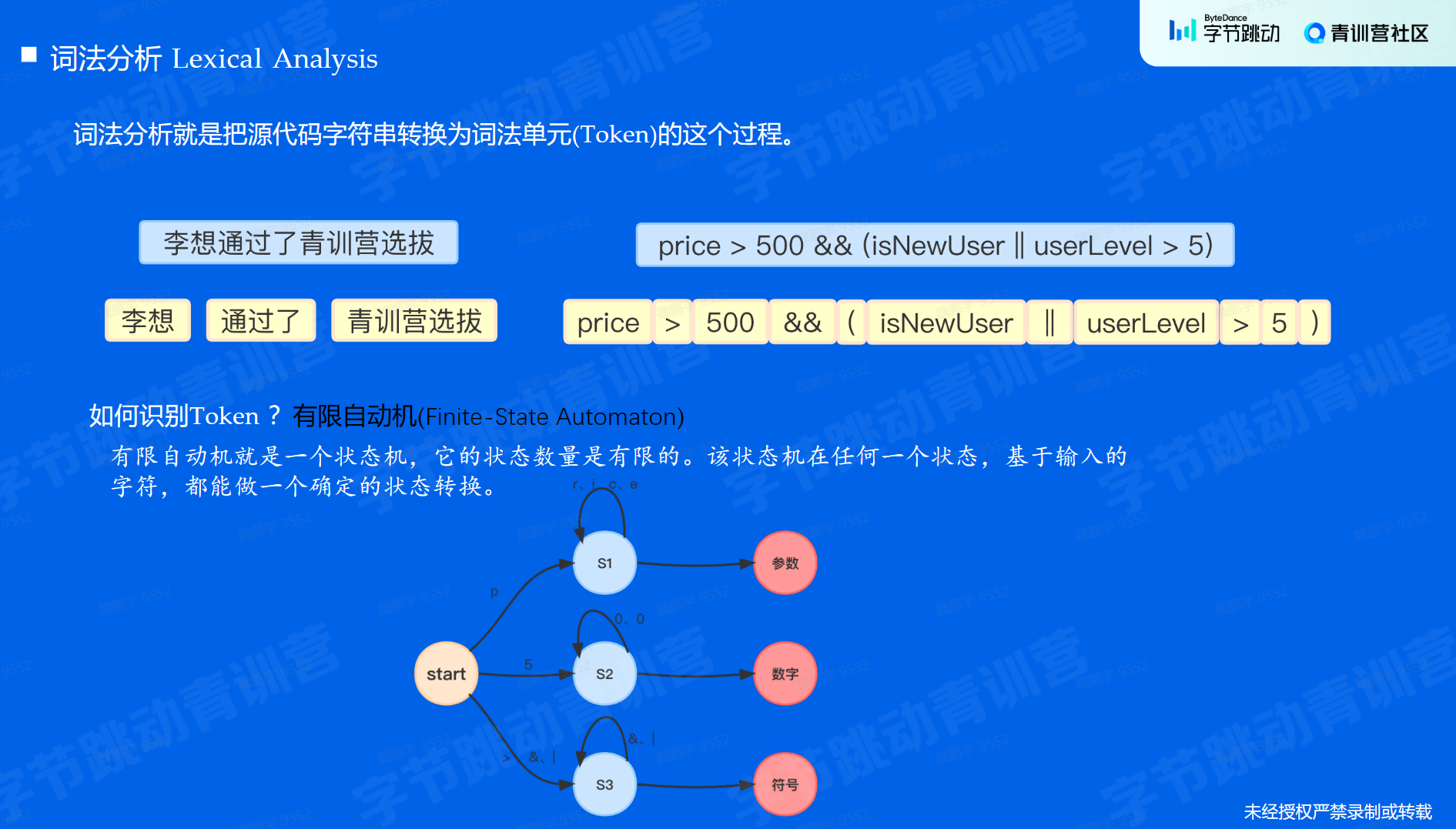
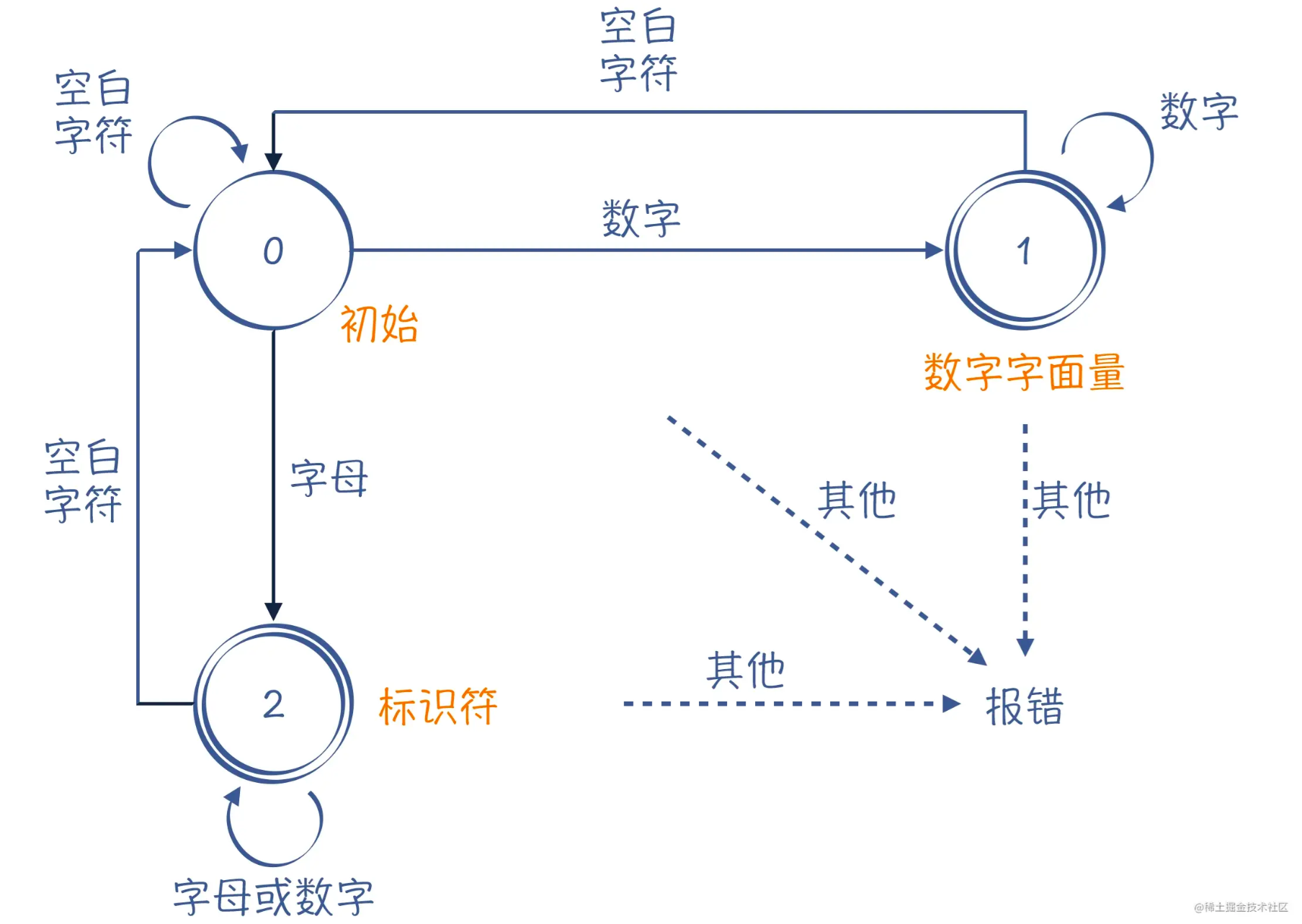
识别token的核心就是有限自动机。
确定的有限自动机就是一个状态机,它的状态数量是有限的。该状态机在任何一个状态,基于输入的字符,都能做一个确定的状态转换。
2.2.2: 语法分析:
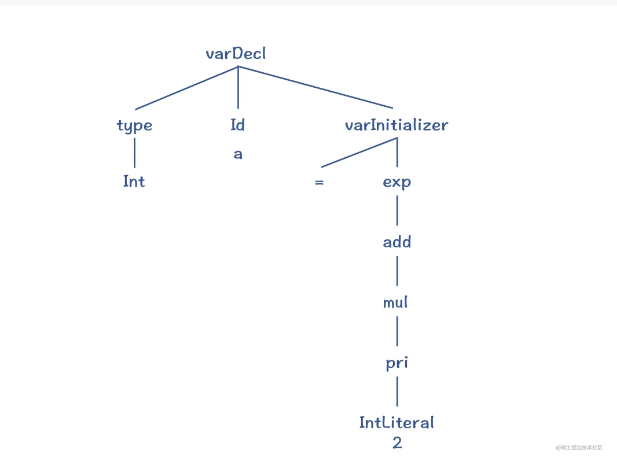
词法分析是识别一个个的单词,而语法分析就是在词法分析的基础上识别出程序的语法结构。这个结构是一个树状结构。这棵树叫做抽象语法树(Abstract Syntax Tree,AST)。树的每个节点(子树)是一个语法单元,这个单元的构成规则就叫“语法”。每个节点还可以有下级节点。
2.2.3: 上下文无关语法:
上下文无关语法 Context-Free Grammar:语言句子无需考虑上下文,就可以判断正确性。
编程语言不使用人类的语言(自然语言),而是采用上下文无关语法。
原因:
1.便于设计编译器。 客观上技术目前无法实现,如果使用了上下文相关文法,那就是真正实现了人工智能,NLP领域将会有重大突破。
2.便于代码开发维护。 如果开发出来的代码像高考的语文阅读理解一样,每个人都有不同的理解,那么,到底哪个才是作者真正想要表达的?如果人类都确定不了含义,那计算机同样也确定不了,最终结果就是错误执行或无法执行。
3.汇编语言/机器语言是上下文无关的。CPU执行指令时,读到哪条执行哪条。如果CPU需要考虑上下文,来决定一个语句到底要做什么,那么CPU执行一条语句会比现在慢千倍万倍。考虑上下文的事情,完全可以用户在编程的时候用算法实现。既然机器语言是上下文无关的,那高级语言也基本上是上下文无关的,可能有某些个别语法为了方便使用,设计成了上下文相关的,比如脚本语言的弱类型。在便于使用的同时,增加了解析器的复杂度。

2.2.3.1:语法简介:
上下文无关语法G:终结符集合T + 非终结符集合N + 产生式集合P + 起始符号S
G由T、N、S和P组成,由语法G推导出来的所有句子的集合称为G语言!
终结符: 组成串的基本符号。可以理解为词法分析器产生的token集合。比如 + Id ( ) 等
非终结符: 表示token的的集合的语法变量。比如 stmt varDecl 等等
| |
产生式:表示形式,S : AB ,就是说S的含义可以用语法AB进行表达
| |
展开(expand):将P(A->u )应用到符号串vAw中,得到新串vu **w
折叠(reduce):将P(A->uu )应用到符号串vuu w中,得到新串vAw
推导(derivate):符号串u 应用一系列产生式,变成符号串v ,则u =>v:S => ab | b | bb
2.2.3.2:巴科斯范式:
BNF是描述上下文无关理论的一种具体方法,通过BNF可以实现上下文无关文法的具体化、公式化、科学化,是实现代码解析的必要条件。
BNF本质上就是树形分解,分解成一棵抽象语法树。
| |
每个产生式就是一个子树,在写编译器时,每个子树对应一个解析函数。
叶子节点叫做 终结符,非叶子节点叫做 非终结符。
2.2.3.3:递归下降算法 Recursive Descent Parsing:
基本思路就是按照语法规则去匹配 Token 串。比如说,变量声明语句的规则如下:
| |
如果写成产生式格式,是下面这样:
| |
| |
对于一个非终结符,要从左到右依次匹配其产生式中的每个项,包括非终结符和终结符。
在匹配产生式右边的非终结符时,要下降一层,继续匹配该非终结符的产生式。
如果一个语法规则有多个可选的产生式,那么只要有一个产生式匹配成功就行。如果一个产生式匹配不成功,那就回退回来,尝试另一个产生式。这种回退过程,叫做回溯(Backtracking)。
2.2.3.4: 类型检查:

