Cwgo 基于 IDL 生成 raw_sql 代码
本文最后更新于 2024-05-29,文章内容可能已经过时。
本文章为参加2024 ospp CloudWeGo社区的赛题:Cwgo 基于 IDL 生成 raw_sql 代码进行的前期准备工作。
主要工作为调研了市面上的各种orm,然后针对新需求,提出支持raw_sql的代码设计。
但是最终没有中选。
初步设计:
提交的第一版文档。
各位老师好,针对根据sql生成框架代码这个问题,我有一些问题和想法:
1.1根据gen,用户输入原生sql
依赖gorm/gen 用户在接口位置,注释时写入原生sql,代替现有的语法。
如果是要达到这个需求,在生成代码的时候可以做参数校验防止sql注入,然后注入参数,使用gorm执行原生sql语句的方式去做。
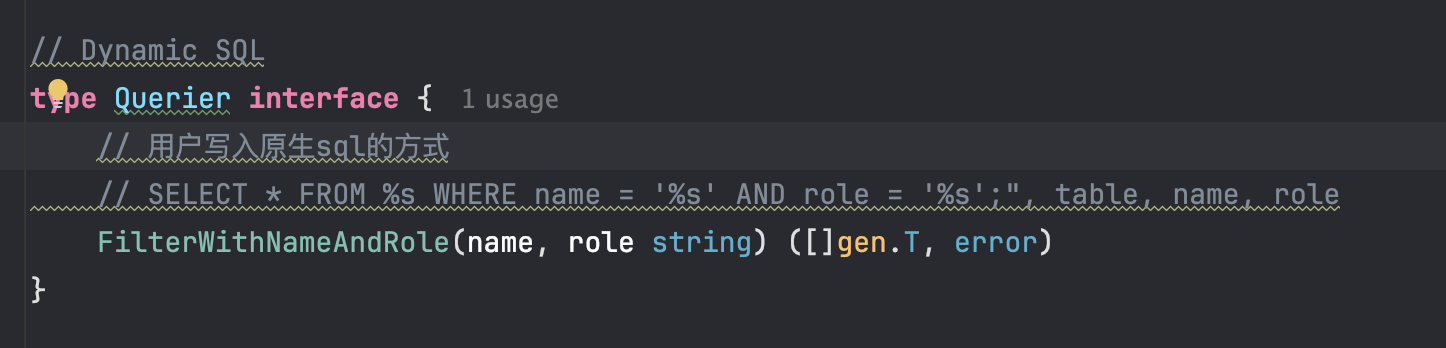
但是这种实现感觉不是特别好,因为它牺牲了动态sql的能力,降低了工具的使用场景。
1.2 根据sql生成curd代码:
按照龙哥在分享会上讲的
基于sql生成一组CURD的API。
对于这个地方如何生成,sql应该取什么类型?
1.2.1 输入建表语句:
市面上常见的我查到的有输入建表语句和一些配置,然后生成相关代码:https://java.bejson.com/generator

1.2.2 输入其他语句:
这种方式我不是很理解要如何去做。
比如我输入一个select语句,那么应该如何去生成curd代码?如果是针对表生成的话,那功能似乎和gen重复,感觉没有必要,其他的方式又没有很好的引入。
1.3 输入动态sql,进行raw_sql转换:
针对现在的代码生成用户看不到sql这个情况,是否可以采用将动态sql转换成raw_sql再去执行的方式实现?
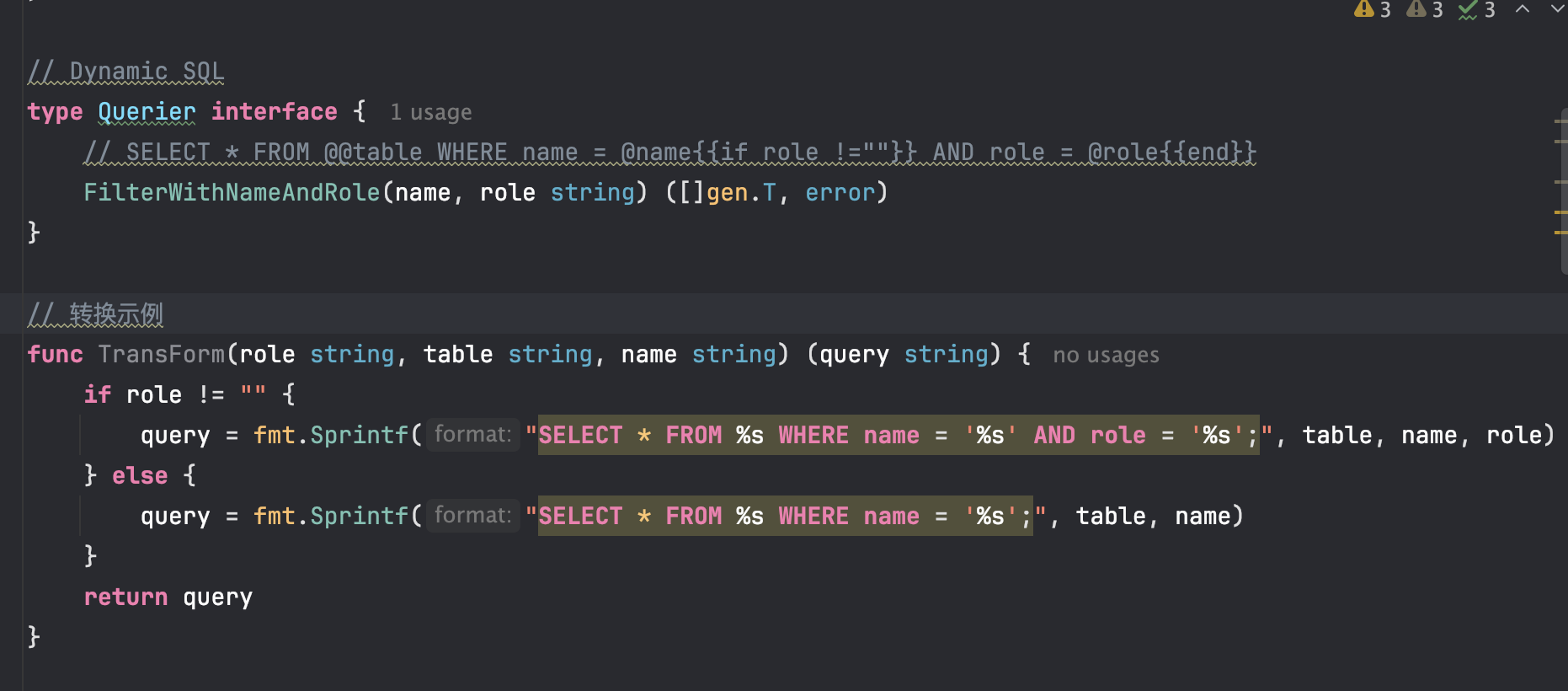
这样做可以发挥动态sql的优势,又可以让用户看到最后的sql。
缺点就是这个转换的函数要自己生成,遇到嵌套等情况可能会过于复杂。
再次调研:各种语言的ORM与新的设计
可以简单的把各种语言的orm的处理分成四部分:
实体类和数据库表之间的映射关系
简单CURD代码的实现
用户自定义普通sql的实现
用户自定义动态sql的实现
1.JAVA:
1.1 Mybaits:
1.1.1 映射:
不做数据库表和实体类之间的映射,需要用户自己控制业务逻辑实现。只做查询结果和查询返回结果类之间的映射关系,通过用户自己指定。
但是提供了Mybatis-Generator生成器去根据数据库表生成实体类和mapper层代码。需要配置一个语法复杂的generator.xml文件实现。比较复杂,不与框架强耦合,几乎没人用。
1.1.2 简单CURD:
不提供此类实现,需要用户自己手写实现,简单CURD代码和普通sql不做区分。
Mybatis-Generator看来要生成基于动态sql的CURD代码,
<insert id="insertSelective" keyColumn="id" keyProperty="id" parameterType="com.homework01.pojo.CourseTeacher" useGeneratedKeys="true"> insert into course_teacher <trim prefix="(" suffix=")" suffixOverrides=","> <if test="id != null">id,</if> <if test="courseId != null">course_id,</if> <if test="empId != null">emp_id,</if> <if test="arrangementDetail != null">arrangement_detail,</if> </trim> <trim prefix="values (" suffix=")" suffixOverrides=","> <if test="id != null">#{id,jdbcType=INTEGER},</if> <if test="courseId != null">#{courseId,jdbcType=INTEGER},</if> <if test="empId != null">#{empId,jdbcType=INTEGER},</if> <if test="arrangementDetail != null">#{arrangementDetail,jdbcType=VARCHAR},</if> </trim> </insert>1.1.3 自定义普通sql:
一共有三种方式实现:原生开发,mapper代理,注解。
1.1.3.1 原生开发:
1.编写实体类,承接返回结果。
2.编写sql:带有占位符的sql语句,通过xml形式实现:
<!-- StudentMapper.xml --><?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="test"> <select id="findAll" resultType="com.yogurt.po.Student"> SELECT * FROM student; </select> <insert id="insert" parameterType="com.yogurt.po.Student"> INSERT INTO student (name,score,age,gender) VALUES (#{name},#{score},#{age},#{gender}); </insert> <delete id="delete" parameterType="int"> DELETE FROM student WHERE id = #{id}; </delete></mapper>在配置中指定查询返回的结果。
一般会采用#{},#{}在mybatis中,最后会被解析为?,其实就是Jdbc的PreparedStatement中的?占位符,它有预编译的过程,会对输入参数进行类型解析(如果入参是String类型,设置参数时会自动加上引号),可以防止SQL注入,如果parameterType属性指定的入参类型是简单类型的话(简单类型指的是8种java原始类型再加一个String),#{}中的变量名可以任意,如果入参类型是pojo,比如是Student类。
而${},一般会用在模糊查询的情景,比如SELECT * FROM
student WHERE name like '%${name}%';它的处理阶段在#{}之前,它不会做参数类型解析,而仅仅是做了字符串的拼接,若入参的Student对象的name属性为zhangsan,则上面那条SQL最终被解析为SELECT * FROM
student WHERE name like '%zhangsan%';由于${}不会做类型解析,就存在SQL注入的风险,比如
SELECT * FROM user WHERE name = '${name}' AND password = '${password}'我可以让一个user对象的password属性为'OR '1' = '1,最终的SQL就变成了:
SELECT * FROM user WHERE name = 'yogurt' AND password = ''OR '1' = '1'因为OR '1' = '1'恒成立,这样攻击者在不需要知道用户名和密码的情况下,也能够完成登录验证
3.编写dao类:
dao类持有SqlSessionFactory对象,每次进行CRUD时,通过SqlSessionFactory创建一个SqlSession调用SqlSession上的selectOne,selectList,insert,delete,update等方法,传入mapper.xml中SQL标签的id,以及输入参数。
4.调用dao层的方法。
1.1.3.2 基于mapper代理开发:
1.编写实体类
2.编写mapper接口,定义需要使用的方法。
3.编写xml文件,编写具体的sql,通过命名规则将xml文件里面的sql和mapper接口里的方法绑定起来。
sql的校验规则和之前一样。
4.调用mapper接口的方法。
这种方式比起原生开发省去了编写一个类的麻烦,变成只需要编写一个接口即可。
1.1.3.3 基于注解开发:
1.编写实体类
2.创建mapper接口,在接口上使用注解放上需要使用的sql语句:
package com.yogurt.mapper;import com.yogurt.po.Student;import org.apache.ibatis.annotations.Insert;import org.apache.ibatis.annotations.Select;import java.util.List;public interface PureStudentMapper { @Select("SELECT * FROM student") List<Student> findAll(); @Insert("INSERT INTO student (name,age,score,gender) VALUES (#{name},#{age},#{score},#{gender})") int insert(Student student);}//多个值使用param注解: @Select("SELECT * FROM student WHERE name like '%${name}%' AND major like '%${major}%'") List<Student> find(@Param("name") String name, @Param("major") String major);注解的开发方式,会将SQL语句写到代码文件中,后续的维护性和扩展性不是很好(如果想修改SQL语句,就得改代码,得重新打包部署,而如果用xml方式,则只需要修改xml,用新的xml取替换旧的xml即可。
1.1.4 自定义动态sql:
开发方式不变,有一套自己的动态sql语法,编写在xml中。
<!-- 示例 --><select id="find" resultType="student" parameterType="student"> SELECT * FROM student WHERE age >= 18 <if test="name != null and name != ''"> AND name like '%${name}%' </if></select>当满足test条件时,才会将<if>标签内的SQL语句拼接上去。
1.2 Mybaits-plus:
1.2.1 映射:
与mybatis一样,不提供直接映射。需要用户自己编写实体类。 AutoGenerator 是 MyBatis-Plus 的代码生成器,通过 AutoGenerator 可以快速生成 Entity、Mapper、Mapper XML、Service、Controller 等各个模块的代码,极大的提升了开发效率,MyBatis-Plus从3.0.3 之后移除了代码生成器与模板引擎的默认依赖,需要手动添加相关依赖,才能实现代码生成器功能。
1.2.2 简单CURD:
框架提供简单CURD的实现,不需要自己写代码。
只需要编写mapper层接口,继承框架提供的接口即可。
package com.fan.demo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.fan.demo.entity.Stu;
public interface StuMapper extends BaseMapper<Stu> {
}提供的方法如下:
// 插入一条记录
int insert(T entity);
// 根据 entity 条件,删除记录
int delete(@Param(Constants.WRAPPER) Wrapper<T> wrapper);
// 删除(根据ID 批量删除)
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 ID 删除
int deleteById(Serializable id);
// 根据 columnMap 条件,删除记录
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
// 根据 whereEntity 条件,更新记录
int update(@Param(Constants.ENTITY) T entity, @Param(Constants.WRAPPER) Wrapper<T> updateWrapper);
// 根据 ID 修改
int updateById(@Param(Constants.ENTITY) T entity);
List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据 columnMap 条件)
List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
// 根据 Wrapper 条件,查询全部记录
List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录。注意: 只返回第一个字段的值
List<Object> selectObjs(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 entity 条件,查询全部记录(并翻页)
IPage<T> selectPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录(并翻页)
IPage<Map<String, Object>> selectMapsPage(IPage<T> page,
@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询总记录数
Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);1.2.3 自定义普通sql:
在mybatis-plus中提了构造条件的类Wrapper,它可以根据自己的意图定义我们需要的条件。Wrapper是一个抽象类,一般情况下我们用它的子类QueryWrapper来实现自定义条件查询。
本质上是通过自己定义的语法,通过query-builder的方式去定义sql语句。这种方式不如手动写sql。
//查询姓名为刘辉军并且性别为男的员工
@Test
public void testSelectOne(){
QueryWrapper<Employee> queryWrapper=new QueryWrapper<>();
queryWrapper.eq("name","刘辉军");
queryWrapper.eq("emp_gender","男");
Employee employee = employeeMapper.selectOne(queryWrapper);
System.out.println(employee);
}
//查询姓名中带有"磊"的并且年龄小于30的员工
@Test
public void testSelectList(){
QueryWrapper<Employee> queryWrapper=new QueryWrapper<>();
queryWrapper.like("name","磊").lt("age",30);
List<Employee> employeeList = employeeMapper.selectList(queryWrapper);
employeeList.forEach(System.out::println);
}
//查询姓刘的或者性别为男,按年龄的除序排序
@Test
public void testSelectList2(){
QueryWrapper<Employee> queryWrapper=new QueryWrapper<>();
queryWrapper.like("name","王")
.or().eq("emp_gender","男")
.orderByDesc("age");
List<Employee> employeeList = employeeMapper.selectList(queryWrapper);
employeeList.forEach(System.out::println);
}
//查询姓刘的并且(年龄小于35或者邮箱不为空)
@Test
public void testSelectList3(){
QueryWrapper<Employee> queryWrapper=new QueryWrapper<>();
queryWrapper.likeRight("name","刘")
.and(wq->wq.lt("age",35).or().isNotNull("email"));
List<Employee> employeeList = employeeMapper.selectList(queryWrapper);
employeeList.forEach(System.out::println);
}1.2.4 动态sql:
和mybatis的一样,要是使用mybatis-plus的话 本来不用写xml 如果突然遇到个复杂逻辑,还得再写。
1.3 Hibernate:
JPA (Java Persistence API)Java持久化API,是一套Sun公司Java官方制定的ORM规范(sun公司并没有实现)。市场上的主流的JPA框架(实现者)有:Hibernate (性能最好)、EclipseTop、OpenJPA。
1.3.1 映射:
Hibernate提供表结构和数据库之间的直接映射关系,通过编写实体类,可以直接生成数据库表。在实体类中通过注解指定表的数据。
1.3.2 简单CURD:
Spring Data JPA 提供了自动化的 CRUD(创建、读取、更新、删除)操作。只需定义接口,并继承 CrudRepository 或 JpaRepository 接口,就可以获得常见的数据库操作方法,如保存实体、查询实体、删除实体等,无需手动编写常见的 CRUD 代码。
CrudRepository接口下的方法如下:
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity);// 1
Optional<T> findById(ID primaryKey);// 2
Iterable<T> findAll();// 3
long count();// 4
void delete(T entity);// 5
boolean existsById(ID primaryKey);// 6
// … more functionality omitted.
}1.3.3 自定义普通sql:
Spring Data JPA 根据方法命名规则自动生成查询语句。例如,根据方法名 findByFirstName(String firstName) 自动生成的查询语句将查找指定 firstName 的实体。还可以使用更复杂的命名规则来生成更复杂的查询语句。
也是通过自己定义的规则去生成sql语句,只不过与mybatis-plus不同的是,把自己定义的部分从方法内部简化到了方法的名字上,更简洁一些。
1.3.4 动态sql:
本质上是使用自己特有的语法进行条件的构造,从而拼接出语句。
public Page<Even> findAll(SearchEven even) {
Specification<Even> specification = new Specifications<Even>()
.eq(StringUtils.isNotBlank(even.getId()), "id", even.getId())
.gt(Objects.nonNull(even.getStatus()), "status", 0)
.between("registerTime", new Range<>(new Date()-1, new Date()))
.like("eventTitle", "%"+even.getEventTitle+"%")
.build();
return personRepository.findAll(specification, new PageRequest(0, 15));
}2.Pyhton:
2.1 Django ORM:
2.1.1 映射:
Django ORM通过模型映射到数据库表。每个属性对应一个表字段。
提供了使用 inspectdb 命令来生成模型代码草稿,从而减少手动编写模型的工作量。不与框架代码强耦合。
2.1.2 简单CURD:
提供了封装好的简单的CURD代码。
# 使用 create 方法(更简洁)
author = Author.objects.create(name='George Orwell', age=46)
# 获取所有对象
authors = Author.objects.all()
# 获取单个对象(如果对象不存在会引发 Author.DoesNotExist 异常)
author = Author.objects.get(id=1)
# 过滤查询
young_authors = Author.objects.filter(age__lt=40)
# 排除某些对象
non_young_authors = Author.objects.exclude(age__lt=40)
# 获取第一个和最后一个对象
first_author = Author.objects.first()
last_author = Author.objects.last()2.1.3 自定义普通sql:
使用 raw 方法执行自定义查询,手写sql语句:
占位符 "%s" 来表示变量,并将实际的变量值作为一个列表传递给 raw 方法。
from myapp.models import Author
# 使用 raw 方法执行自定义 SQL 查询
sql = "SELECT * FROM myapp_author WHERE age > %s"
authors = Author.objects.raw(sql, [30])
for author in authors:
print(author.name, author.age)2.1.4 自定义动态sql:
有两种实现,可以通过手动编写拼接sql的业务逻辑去做:
from django.db import connection
def execute_dynamic_sql(min_age=None, max_age=None, name=None):
sql = "SELECT * FROM myapp_author WHERE 1=1"
params = []
if min_age is not None:
sql += " AND age >= %s"
params.append(min_age)
if max_age is not None:
sql += " AND age <= %s"
params.append(max_age)
if name is not None:
sql += " AND name = %s"
params.append(name)
with connection.cursor() as cursor:
cursor.execute(sql, params)
rows = cursor.fetchall()
return rows也可以通过框架自带的动态查询:本质上还是使用自己定义的语法:
from myapp.models import Author
from django.db.models import Q
def get_authors_by_orm(min_age=None, max_age=None, name=None):
query = Q()
if min_age is not None:
query &= Q(age__gte=min_age)
if max_age is not None:
query &= Q(age__lte=max_age)
if name is not None:
query &= Q(name=name)
return Author.objects.filter(query)
# 使用该函数执行查询
authors = get_authors_by_orm(min_age=30, max_age=50, name="George Orwell")
for author in authors:
print(author.name, author.age)3.Go:
3.1 Gorm:
3.1.1 映射:
gorm通过AutoMigrate提供从结构体到数据库表的映射,可以在建立好结构体之后,自动在数据库建表。
3.1.2 简单CURD:
gorm自己提供了简单的curd代码。
DB.Model(&User{}).Create(map[string]interface{}{
"Name": "jinzhu", "Age": 18,
})
// batch insert from `[]map[string]interface{}{}`
DB.Model(&User{}).Create([]map[string]interface{}{
{"Name": "jinzhu_1", "Age": 18},
{"Name": "jinzhu_2", "Age": 20},
})3.1.3 自定义普通sql:
提供执行的方法,使用?作为占位符。
db.Raw("SELECT * FROM users WHERE age > ?", 18).Scan(&users)3.1.4 自定义动态sql:
采用链式拼接的思路实现,语法相对比较简单。
func SearchCommodityByQuery(req model.SearchCommodityReq) (commodity []model.Commodity, err error) {
name := req.Name
introduction := req.Introduction
classify := req.Classify
query := global.GB_MDB.Model(&commodity)
if name != "" {
query = query.Where("name like ?", "%"+name+"%")
}
if introduction != "" {
query = query.Where("introduction like ?", "%"+introduction+"%")
}
if classify != "" {
query = query.Where("classify like ?", "%"+classify+"%")
}
err = query.Find(&commodity).Error
return
}3.2 gorm/gen:
3.2.1 映射:
提供数据库到结构体的映射。使用gen可以指定表名后自动读取并生成对应结构体。
3.2.2 简单CURD:
提供,与gorm相同。
// u refer to query.user
user := model.User{Name: "Modi", Age: 18, Birthday: time.Now()}
u := query.Use(db).User
err := u.WithContext(ctx).Create(&user) // pass pointer of data to Create
err // returns error3.2.3 自定义普通sql:
通过自定义注释实现。使用自己的语法。
定义之后生成后使用。
3.2.4 自定义动态sql:
与普通sql一样,基本不做区分。
4.新的设计
4.1.映射:
根据gorm官网地址上说的,正常的写法是先写数据模型,然后由数据模型自动同步生成到数据库中,但是这样的工作量会比较大,对于写后端的人来说都熟悉sql语句,正常来说都是先自己手动创建表,利用工具将表字段同步到项目实体类中。
针对各种情况不同,提供双向映射。
既可以通过数据库表映射到go结构体(参考mybatis的实现),也可以通过结构体/idl等文件格式映射到数据库表(参考gorm的实现)
尝试仿照mock/gen方式,通过命令行方式进行生成。
4.2.简单CURD代码:
自动生成,采取生成时生成sql语句,最终执行sql语句的形式。
4.3.自定义普通sql:
采用类似Hibernate与gorm/gen的方式实现。不需要再写注释
用户在接口里按照一定的命名方式定义好,根据接口生成实现方法,在实现中生成sql语句。用户调用接口中的方法即可。生成的sql语句包含limit等一般orm屏蔽的关键字,参数只使用占位符实现,其他部分和原生sql语句没有区别。生成的sql语句以注释的方式的方式出现在接口上方,用户可以修改,修改之后重新进行代码生成即可。(此处也可以采用类似于mybatis的文件管理方式,但是对于快速搭建的需求来说,采用类似注解开发的方式会更直观一点)
对于接口中的参数,不使用占位符,用户自己定义传入参数和返回值的类型,在代码生成时做类型检查,然后拼接sql。
对于复杂查询(比如联表,嵌套等),思路是如果能直接写占位符sql,就让用户通过占位符sql实现,类似于现在的gorm/gen 不同的是直接把sql语句写在接口中方法的上方,然后代码生成去做参数类型检查和拼接sql的工作,相当于比上面少了一步。
此种设计的思路就是简单的逻辑追求极致的简单,而相对复杂的逻辑则提供更加动态的能力。
4.4.自定义动态sql:
(应该是出现最少的场景)
同样是在接口上定义,使用特殊的注解标签标明这是一个动态sql。
使用自己的动态sql语法。
代码生成时,根据这个动态sql的语法转换成真实的sql语句,这个转换的业务逻辑实现放在代码生成的前列。
