简历文档v2.0
本文最后更新于 2024-04-25,文章内容可能已经过时。
简历文档v2.0
自我介绍:
面试官您好,我叫魏鹏宇,来自哈尔滨工业大学。
我是大一下学期开始学习后端开发,并加入了我们学校的werun实验室,实验室分本科生研究生 前后小程序安卓四个方向,主要从事软件开发,接项目等工作。
大二下学期开始担任实验室主席。主持实验室纳新例会项目开发等日常活动,并作为项目负责人完成了两个大型的校企合作项目与维护多个老项目。并为实验室工作流程,引入新的技术等。andulir
然后在后续的开发中,感觉相比起业务,自己对基础架构和云原生更感兴趣一点,就主要开始从事此方向。
然后寒假找的go的实习,主要做的也是基础架构和代码改造相关的工作。
未来准备暑期实习,然后就业。
2024暑期实习简历。
吸取上次的经验 ,文档太多,根本不能在面试的时候看得到细节,这次重新构思一下,配合思维导图的方式,达到提词器一样的作用。
.png)
1.实验室相关:
1.1 Andulir:
在项目实践中开发的开源项目.
用于本地测试和项目上线的自动化测试.
使用流程:
引入
注解
启动项目
修改xml配置
重新启动
架构:
数据解析器:通过注解搜索到方法 生成对应的xml结构 持久化为一个xml文件.
数据生成器:根据xml文件 随机的生成测试数据
测试工具:
CommandLineRunner 是 Spring 框架中用于构建命令行应用程序的接口。它属于 org.springframework.boot 包,提供了在 Spring Boot 应用程序启动时运行代码的方式。该接口只包含一个方法:run
@Autowired
private ApplicationContext applicationContext;测试的时候通过反射生成的对象不能注入 所以要通过上面的方法获取bean.
然后还有 git diff 命令 openfegin 前端 自动化测试. 管理测试用例的概念.
1.2 CI/CD 与DEVOPS:
DevOps中的Dev指的是Development(开发),Ops指的是Operations(运维),用一句话来说,DevOps就是打通开发运维的壁垒,实现开发运维一体化。
CI/CD 是持续集成和持续交付/部署的缩写,旨在简化并加快软件开发生命周期。 持续集成(CI)是指自动且频繁地将代码更改集成到共享源代码存储库中的做法。 持续交付和/或持续部署(CD)是一个由两部分组成的过程,涉及代码更改的集成、测试和交付。
1.3 jenkins:
最好是能实现启动的时候自动跑测试用例
特殊的使用方式 构建在甲方服务器上。只做触发器和拉取之用。
源码管理 触发器 构建 前/中/后 等操作
配置时遇到的超级大坑 :linux source etc/profile相关
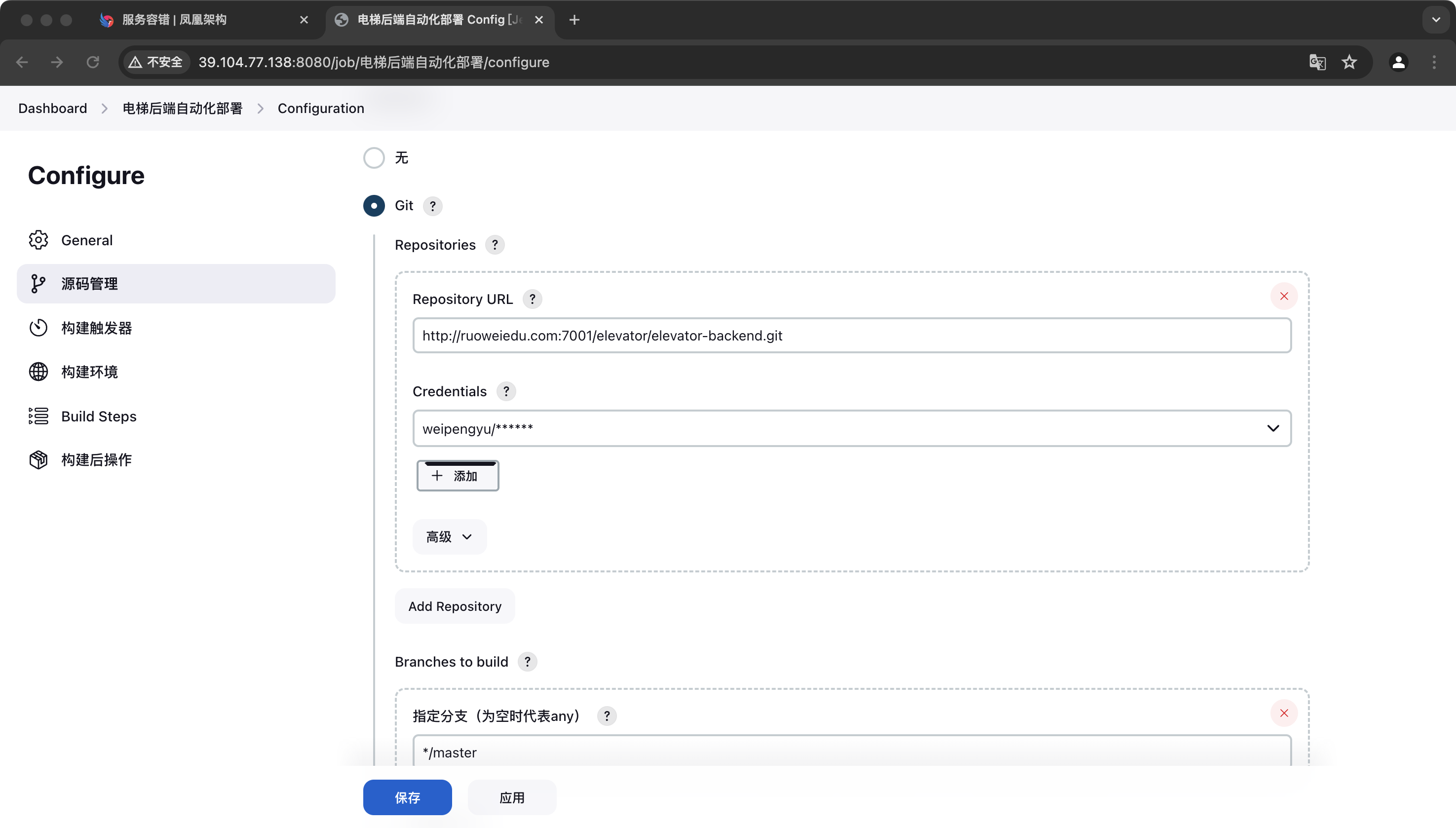
后续的升级:分微服务模块操作git diff命令配合shell脚本
1.4 工作流:git-flow:
2.实习:
2.1 断路器:
Hystrix断路器设计模式 内部维护map
断路器的基本思路是很简单的,就是通过代理(断路器对象)来一对一地(一个远程服务对应一个断路器对象)接管服务调用者的远程请求。断路器会持续监控并统计服务返回的成功、失败、超时、拒绝等各种结果
2.2 ab测试:
A/B测试为一种随机测试,将两个不同的东西(即A和B)进行假设比较。 该测试运用统计学上的假设检定和双母体假设检定。 A/B测试可以用来测试某一个变量两个不同版本的差异,一般是让A和B只有该变量不同,再测试其他人对于A和B的反应差异,再判断A和B的方式何者较佳。
同样是维护接口状态 通过传入的参数进行转向。
2.3 init:
早期开发过程中使用 有一些问题
顺序不确定 改造方案 输出与改名
2.4 kafka客户端:
基于"github.com/segmentio/kafka-go"
1.函数参数:
以前是创建对象,然后
m, err := c.reader.FetchMessage(ctx)现在是使用函数参数封装对象
直接定义符合条件的方法传入即可。
2.ctx取消:
日志管理
https://blog.csdn.net/weixin_42216109/article/details/123694275
3.编写接口 :
支持mock能力。维护接口状态 调用一个接口 传入相应的key 就会去调用kafka相关的方法 达到分层mock的功能
应用场景:
微服务之间 实际业务中,各个模块之间的内部测试无法贯通,可以解耦合,方便测试。
2.5 单元测试:
重要性:业务逻辑闭合
公司当时情况
技术选型:gomonkey go mock
mockgen代码生成
简化调用方式:
1.结构体⽅法方式:类似ioc. 调用较为复杂
2.封装redis+cache
3.全局变量的方式 在go-mock中对全局变量二次初始化
redis处理:redis-mock 不如go-mock好用 而且自带嵌套情况 mockgen生成起来有难度
2.6 全链路mock方案:
应用场景:依然是微服务之间各自依赖的问题
带本地缓存和redis缓存 业务逻辑不好测试
1.缓存屏蔽
2.远端数据源发送:是正常,由网关层做转发,或者直接转发
使用环境变量做双重测试,怕上正式和灰度了有问题。
根据ctx实现 用一个新的对象 分成mockclient和trueclient
redis的client会随着版本更新而更新 还有client问题 返回管道对象操作 无所谓
2.7业务:
业务 ktv 用户kid逻辑维
全局id生成 kid
分布式锁加定时任务 定时生成五万条id存进redis
先生成id储存起来
使用的时候去取
暗词优化:三方数据流转
会员中心歌曲下发
臻享会员栏目内容:
和cms疯狂讨论,版本控制问题,工作流程有问题
3.内存数据库相关:
3.1 背景:
通过公司业务 看到了内存数据库的价值 前台服务 加上mit6.824
3.2 装饰者模式 cmd命令:
参考go-micro
3.3 raft:
应用场景 选主 get/set 异常恢复
线性一致性优化:读请求同样作为一个提案走一遍 Raft 流程,当这次读请求对应的日志可以被应用到状态机时,leader 就可以读状态机并返回给用户了。
https://juejin.cn/post/6906508138124574728?share_token=439a3339-0bc1-49b3-aa1a-5ddef36263f9
3.4 锁
互斥锁
读写锁
全局map锁
没有锁
3.5 缓存预热:
注入获取数据源相应的方法,在函数的init中使用。
匿名函数的机制,可以实现丰富的注入类型。
3.6 缓存异常
布隆 穿透
singlefilght 击穿 请求合并 与断路器联合使用
3.7 client:
把学到的东西应用到生活中。
4.尤利西斯:
网络 veth linux bridge
5.电梯:
5.1 oauth2与rbac:
选用原因:成熟可靠,确实有外部对接的需求。
tob与toc的业务差距。
5.2 缓存:
cache aside。
5.3 日志系统
定时任务分析
5.4 自动化迁移:
原有的数据库是在postgres,新系统因为国产化需求需要进行数据库的迁移.
主要是一个shell 脚本 一个python脚本 一个java脚本实现的.
需求:按列迁移.
方案: 首先给到的是一整个数据库的备份
python脚本切分文件
找到想要的表
java改变文件格式
导入postgers
shell启动达梦 最后一步需要手动迁移.
5.5 外部对接方案:
电梯保险数据接收.
工单写入
电梯运行状态等
安全性:appkey secret
幂等性: redis自增函数获取唯一的操作id
携带id访问内部接口
分布式锁.保证幂等性.
5.6 对接支付宝:
应用场景:商户购买图片翻译,文字翻译等服务.
首先获取appid,appkey,appsecret.我是一开始是使用沙盒的参数,测试完成后换成公司正式的. 把这些通过一个配置类存起来.
然后编写接口,主要有两个方法
一个是发起支付的方法,一个是支付完成后,支付宝平台设置回调的方法.
因为都是自己调用的,所以url可以随便写.
传入订单号,返回一个HTML页面 用户扫码支付后,支付宝异步调用系统给出的接口. 编写完成后,在本地测试回调的时候,还涉及到了内网穿透问题.
内网穿透的核心原理在于将外网 IP 地址与内网 IP 地址建立联系
我当时是使用的ngrok.通过反向代理的方式实现的.
正向代理是代理客户端,反向代理是代理服务器.
ngrok 是一个反向代理,通过在公共的端点和本地运行的 Web 服务器之间建立一个安全的通道。
然后就是退款,调用支付宝的退款接口,然后等待返回结果.这也是异步的.
5.7 对接机器翻译:
和对接支付宝差不多
都是使用appkey和appsecret的方式去获取支付宝的翻译api的client.
然后调用翻译接口进行翻译.
但是有个大坑.
就是如果不使用maven等方式引入依赖,(会有很多个依赖)会出现版本不匹配问题,看官网的文档也解决不了.mavenrepository上寻找也找不到.
最后联系的阿里的工作人员来解决的.
5.8 websocket:
工单完成通知 order模块通知 unit模块
大屏展示功能 通过socket实现工单监控数据的变化.
5.9 k8s部署:
Kubernetes(K8s)是一个开源的容器编排平台,用于自动化容器化应用程序的部署、扩展和运维。以下是使用Kubernetes部署项目的一般流程:
准备工作:
安装和配置kubectl:kubectl是与Kubernetes集群进行交互的命令行工具。你需要安装并配置kubectl,以便连接到你的Kubernetes集群。
安装和配置Kubernetes集群:你可以选择使用各种工具,如Minikube(本地开发和测试)、kubeadm、或云服务提供商的托管Kubernetes集群。
容器化应用:
将你的应用程序容器化:使用Docker或其他容器化工具将你的应用程序打包为Docker镜像。确保Docker镜像包含应用程序的所有依赖项。
创建Kubernetes配置文件:
编写Kubernetes配置文件(YAML格式):定义Deployment、Service、ConfigMap等Kubernetes资源的配置。配置文件描述了你的应用程序的部署和服务配置。
部署应用程序:
使用kubectl apply命令应用你的Kubernetes配置文件:这将在Kubernetes集群中创建相应的资源(Deployment、Service等)来部署和运行你的应用程序。
bashCopy codekubectl apply -f your-deployment.yaml
kubectl apply -f your-service.yaml